import requests
The from LXML import etree
HEADERS={
'the user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36 '
}
URL='https://blog.csdn.net/weixin_45949073/article/list/'
# response=requests. Get (url=url, headers=headers). The text
Response=requests. Get (url=url, headers=headers). The decode (' utf-8)
HTML=etree. HTML (response)
Detail_ur=HTML. Xpath ("//div [@ class='pagination - box']//div [@ class='UI - the paging - container']//ul//li/@ data - page ") # can be extracted, i.e., as the chart, but the output is an empty list
Print (detail_ur)
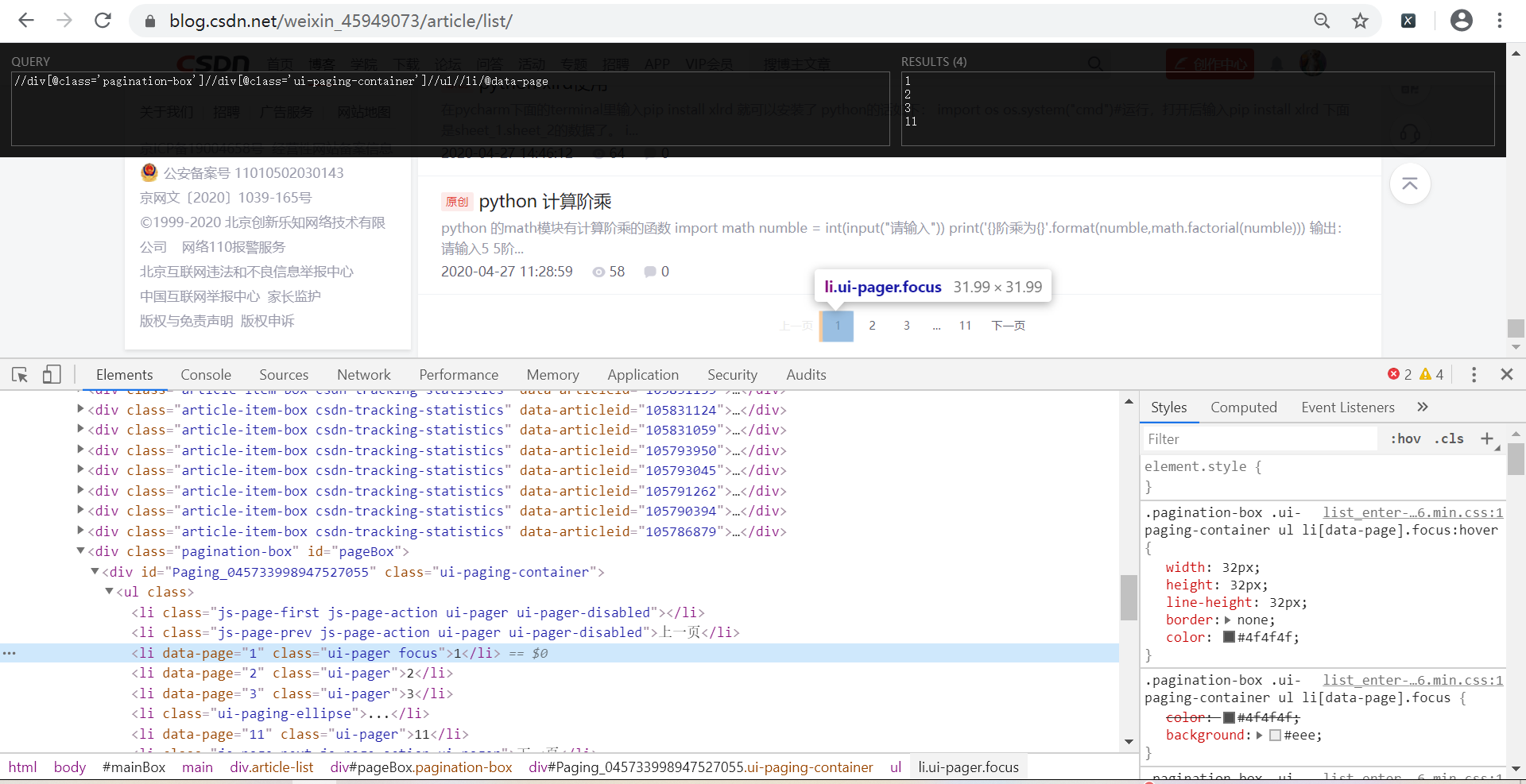
CodePudding user response:
As shown//div [@ class='pagination - box']//div [@ class='UI - the paging - container']//ul//li/@ data - page ") in the XPath plug-ins can be retrieved, but nothing output code, alas, good ah,CodePudding user response:
This page should be a dynamic loading out!!!! Not in the source code, you look at the source code, you'll know
CodePudding user response: