Home > other > For two of the python programming problem
For two of the python programming problem
Time:09-18
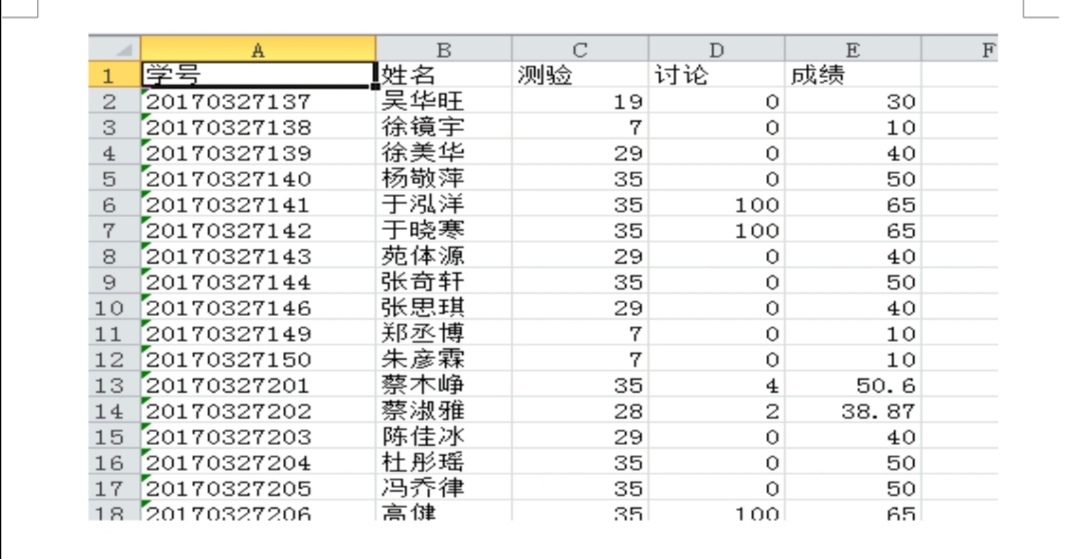
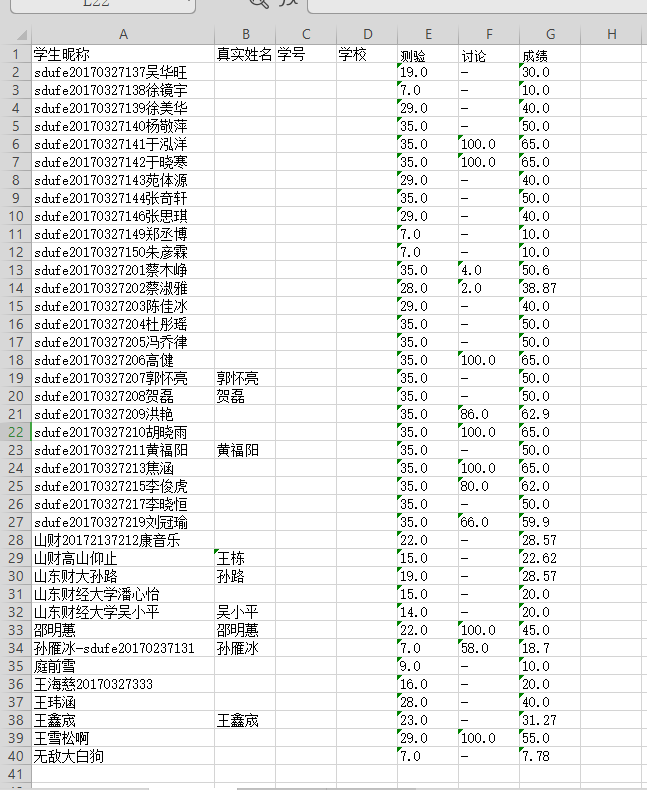
Python topic for help 1. The "homework - raw scores. XLSX file" nickname for processing, will begin with sdufe nickname, sdufe 11 behind the name out behind the student id and student id, and test, discussion, three data into numerical scores, "-" into "0", wrote "export achievement. XLSX file," run results are as follows: Original score for
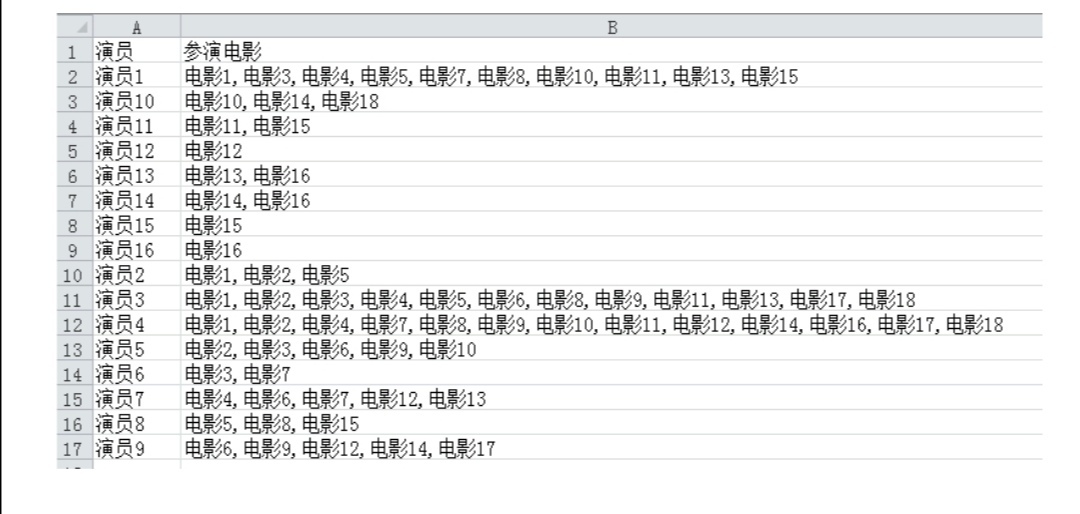
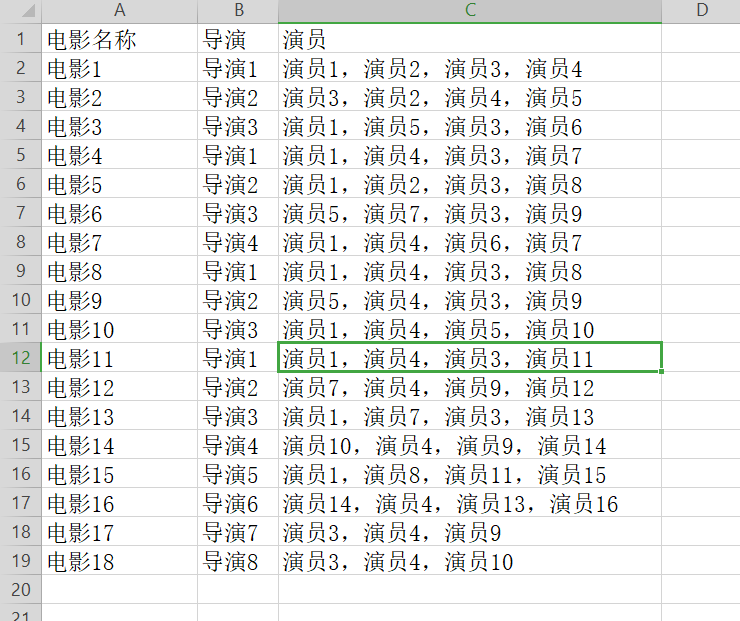
2. A given film director, actor. XLSX file, statistics every actor in the movie list, write "cast in the movie. XLSX" excel file, run results as follows: For a given file form
CodePudding user response:
Import XLRD library, to excel read line by line, simple judgment should go
Dfnew=pd. DataFrame (list (zip (df_code df_name, df_test, df_discuss, df_grade)), the columns=[' student id ', 'name', 'test', 'discussion', 'performance']) Dfnew. To_excel (r "c: \ export grades. XLSX", the index=False)
df=pd read_excel (r "c: \ film director, actor. XLSX") D={} For the index, row in df iterrows () : The actor, movie=row [' actors'], row [' movie name '] For n in the actor. The split (', ') : If d.g et (n, 'f')=='f' : [n]=d movie The else: If movie not in d [n] : [n] +=", "+ d movie
Dg=pd. DataFrame ([(k, v) for k, v in d.i tems ()], the columns=[' actors', 'movie']) Dg. To_excel (r "c: \ cast in the movie. XLSX", the index=False)