I have a df, and I want to compare 1 column to each of the remaining columns in the df, count and calculate the ratio.
import numpy as np
import pandas as pd
indices = (1,2,3,4,5,6)
col = ["gender", "under 15", "homework finishing"]
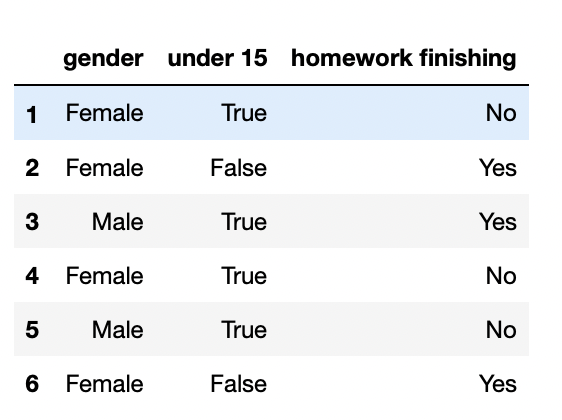
data = (["Female", True, "No"], ["Female", False, "Yes"], ["Male", True, "Yes"], ["Female", True, "No"],
["Male", True, "No"], ["Female", False, "Yes"])
df = pd.DataFrame(data, index = indices, columns = col)
And I want the result to be:
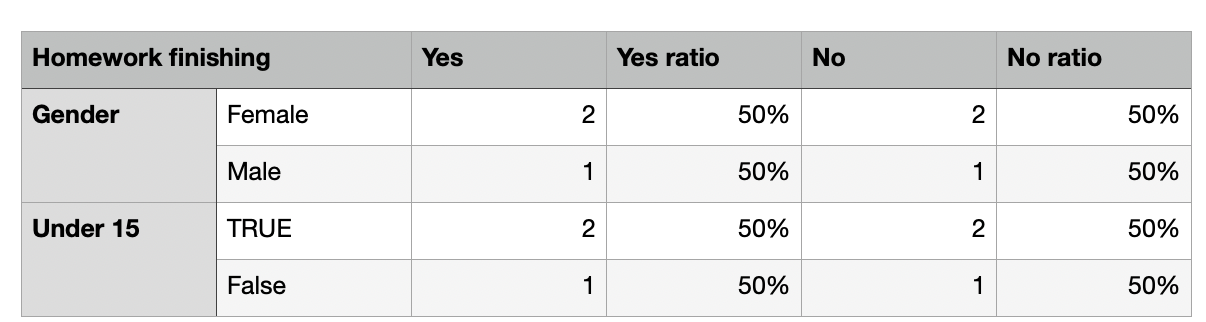
Initially, I tried using multiindex but failed. Or should I use groupby?
I am wondering if it is possible to do this by pandas? Any hint or help is welcome
CodePudding user response:
I'm not really sure how you want to divide it, since your first column has both Gender and Under 15 as indices, and the values are split into halves between them somehow (it doesn't add up with your first table example either).
But this kind of resembles your example:
>>> df.groupby(["gender", "homework finishing"]).size().unstack()
homework finishing No Yes
gender
Female 2 2
Male 1 1
>>> df.groupby(["under 15", "homework finishing"]).size().unstack()
homework finishing No Yes
under 15
False NaN 2.0
True 3.0 1.0
You of course still need to add the percentage division, but I'm sure you can manage that.