Here's what the pandas table look like:
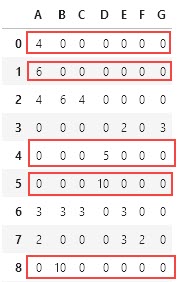
As you can see the red marked rows have any of all six column values set to '0'. I want to select only non-red rows and filter these red ones out.
I can't seem to figure if there's in-built or, easy way to do it.
CodePudding user response:
Use a boolean mask as suggested by @Ch3steR and use .iloc or .loc to select a subset of columns:
# Minimal sample
>>> df
A B C D E F G H I J
0 4 0 0 0 0 0 0 1 3 2 # Drop
1 4 6 4 0 0 0 0 0 0 0 # Keep
# .iloc version: select the first 7 columns
>>> df[df.iloc[:, :7].eq(0).sum(1).lt(6)]
A B C D E F G H I J
1 4 6 4 0 0 0 0 0 0 0
# .loc version: select columns from A to G
>>> df[df.loc[:, 'A':'G'].eq(0).sum(1).lt(6)]
A B C D E F G H I J
1 4 6 4 0 0 0 0 0 0 0
Step by Step:
# Is value equal to 0
>>> df.loc[:, 'A':'G'].eq(0)
A B C D E F G
0 False True True True True True True
1 False False False True True True True
# Sum of boolean, if there are 3 True, the sum will be 3
# sum(1) <- 1 is for axis, the sum per row
>>> df.loc[:, 'A':'G'].eq(0).sum(1)
0 6 # 6 zeros
1 4 # 4 zeros
dtype: int64
# Are there less than 6 zeros ?
>>> df.loc[:, 'A':'G'].eq(0).sum(1).lt(6)
0 False
1 True
dtype: bool
# If yes, I keep row else I drop it
>>> df[df.loc[:, 'A':'G'].eq(0).sum(1).lt(6)]
A B C D E F G H I J
1 4 6 4 0 0 0 0 0 0 0