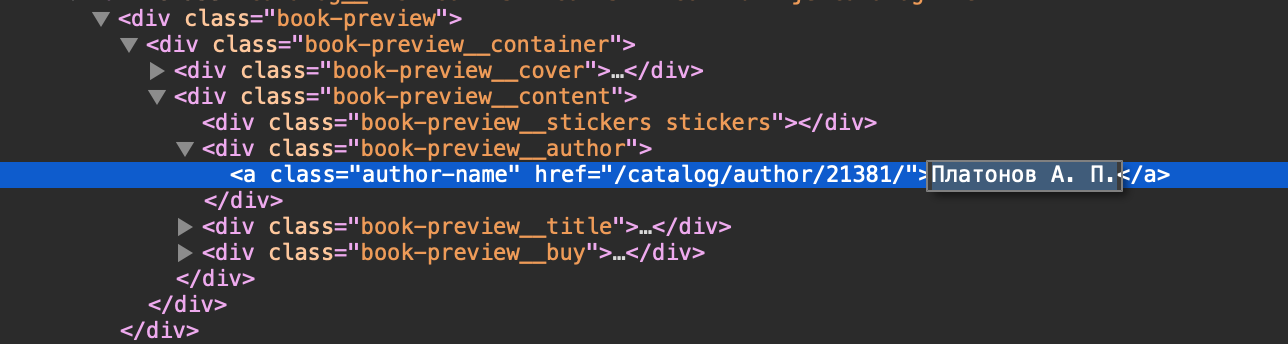
I need to get text "Платонов А.П." Here's my code by far.
import requests
from bs4 import BeautifulSoup
from pip._internal.network.utils import HEADERS
URL = "https://www.moscowbooks.ru/books/?sortby=name&sortdown=false"
HEADERS = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15", "accept" : "*/*"}
HOST = "https://www.moscowbooks.ru"
def get_html(url, params=None):
r = requests.get(url, headers = HEADERS, params = params)
return r
def get_content(html):
soup = BeautifulSoup(html, "html.parser")
items = soup.find_all("div", class_ = "catalog__item")
books = []
for item in items:
author_check = item.find("a", class_="author-name")
if author_check:
author = author_check.get_text()
else:
author_check = "Автор не указан"
books.append({
"title": item.find("div", class_ = "book-preview__title").get_text(strip=True),
"author": author_check,
"link": HOST item.find("a", class_ = "book-preview__title-link").get("href"),
"cost": item.find("div", class_="book-preview__price").get_text(strip=True),
})
print(books)
print(len(books))
def parse():
html = get_html(URL)
if html.status_code == 200:
get_content(html.text)
else:
print("Error")
parse()
I get problems with author, because it get like this:
<a class="author-name" href="/catalog/author/21381/">Платонов А. П. </a>
Also need a little help with price because sometimes it gets '2\xa0274' instead of '2 274'.
CodePudding user response:
The problem is that you define "author": author_check in your dictionary, while author_check = item.find("a", class_="author-name") and author = author_check.get_text(). You can change your for loop into something like this
for item in items:
author_check = item.find("a", class_="author-name")
if author_check:
author = author_check.text
else:
author = "Автор не указан"
For you issue with the display of the prices, you can just replace \xa0 with a comma or space.
"cost": item.find("div", class_="book-preview__price").get_text(strip=True).replace(u"\xa0", ",")
CodePudding user response:
I've had to deal with similar problem. You can do the following:
author = author_check.get_text().split('>')[-2].split('<')[0]
You might have to substitute -2 with -1.