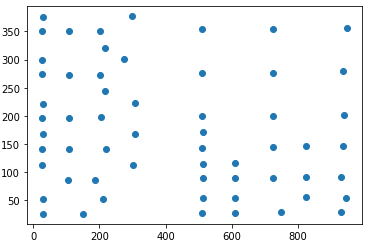
Have an array of point which are plotted as below . There are column structures in the set of point.
How can these points be grouped into different columns?
np.array([[151, 26],[ 30, 26],[511, 27],[747, 30],[609, 28],[930, 30],
[ 30, 52],[211, 53],[513, 54],[608, 54],[824, 56],[946, 55],
[106, 87],[187, 87],[512, 89],[609, 90],[725, 90],[823, 92],
[931, 92],[ 28, 113],[301, 113],[512, 115],[609, 116],[ 28, 142],
[107, 141],[220, 142],[511, 143],[724, 145],[823, 146],[937, 146],
[ 29, 168],[308, 168],[512, 171],[ 28, 197],[107, 197],[205, 198],
[511, 199],[724, 200],[940, 201],[ 29, 222],[307, 223],[217, 244],
[107, 273],[ 28, 274],[201, 273],[511, 276],[725, 277],[937, 279],
[ 28, 299],[273, 301],[218, 321],[ 28, 351],[107, 350],[201, 351],
[511, 354],[723, 354],[947, 356],[ 29, 376],[297, 377]])
Expected output is
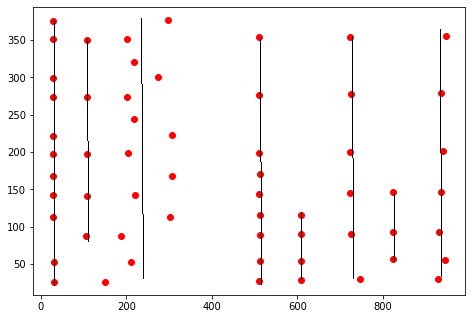
where the line is representing each group of coordinates which visually forms a column .
Thanks in advance for your time – if I’ve missed out anything, over- or under-emphasized a specific point let me know in the comments.
CodePudding user response:
From Scratch
# Create variables
grouped = []
unique = {}
# Get all unique x values and store y as array in dictionary
for point in points:
unique[point[0]] = unique.get(point[0], []) point[1]
# Convert the x's into columns of points
for x in unique:
grouped.append([[x, y] for y in unique[x]])
# Extra polishing
grouped = np.array(grouped)
This creates a new NumPy array:
data = [columns [points within columns]]
Note that this does not handle the re-graphing because not enough information was provided for that section, only the splitting into groups.
CodePudding user response:
You can use a defaultdict to append to a list for each point you find in a column.
from collections import defaultdict
d = defaultdict(list)
for point in array:
x, _ = point
d[x].append(point)
grouped_by_columns = list(d.values())
CodePudding user response:
To group the columns by points (grouping by x), you can do something like this.
xy = np.array([
[151, 26],[ 30, 26],[511, 27],[747, 30],[609, 28],[930, 30],
[ 30, 52],[211, 53],[513, 54],[608, 54],[824, 56],[946, 55],
[106, 87],[187, 87],[512, 89],[609, 90],[725, 90],[823, 92],
[931, 92],[ 28, 113],[301, 113],[512, 115],[609, 116],[ 28, 142],
[107, 141],[220, 142],[511, 143],[724, 145],[823, 146],[937, 146],
[ 29, 168],[308, 168],[512, 171],[ 28, 197],[107, 197],[205, 198],
[511, 199],[724, 200],[940, 201],[ 29, 222],[307, 223],[217, 244],
[107, 273],[ 28, 274],[201, 273],[511, 276],[725, 277],[937, 279],
[ 28, 299],[273, 301],[218, 321],[ 28, 351],[107, 350],[201, 351],
[511, 354],[723, 354],[947, 356],[ 29, 376],[297, 377]])
n = np.unique(xy[:,0])
cols = { i: list(xy[xy[:,0]==i,1]) for i in n }
This creates a dictionary containing column as keys and its corresponding y values. If you want to group by y to get rows then you can simply flip the 0's and 1's and you'll get group by y.
Then, to re-print the graph, you can do this (There is probably a better way of doing this)
x, y = np.array([]), np.array([])
for i in cols.items():
x = np.append(x, [i[0]] * len(i[1]))
y = np.append(y, (i[1]))
plt.scatter(x, y)
plt.show()
Which gives back the original graph.