This question is related to this 
My problem is that whenever I compute a binned mean (also tweaking bins) the results are mainly nan values because my data contains intervals of nans that I don't really want to discard. Here's some code that reproduce the problem:
from scipy.stats import binned_statistic
import numpy as np
#defining a generic data similar to mine
a=np.array([0.1, 0.15, 0.17, 0.2, 0.3, 0.4, np.nan, 0.12, 0.15, 0.17, 0.22, np.nan, 0.37, np.nan, 0.12, 0.15, 0.17, 0.17, 0.35, 0.42, np.nan])
b=np.linspace(1,len(a),len(a))
plt.scatter(b,a)
plt.hlines(np.nanmean(a),b[0],b[-1], linestyles='--')
plt.show() #you can uncomment this line to separate the plots.
#filtering nans
nana= a[~np.isnan(a)]
nanb= np.linspace(1,len(nana),len(nana))
plt.scatter(nanb,nana, marker='o')
plt.hlines(np.nanmean(a),b[0],b[-1], linestyles='--')
#calculating a binned mean
bmean_nana = binned_statistic(nanb, nana,
statistic='mean',
bins=3,
range=(0, len(nana)))
bin_centers = bmean_nana.bin_edges[1:] - (abs(bmean_nana.bin_edges[0]-bmean_nana.bin_edges[1]))/2
plt.scatter(bin_centers, bmean_nana.statistic, marker='x', s=90)
with output:
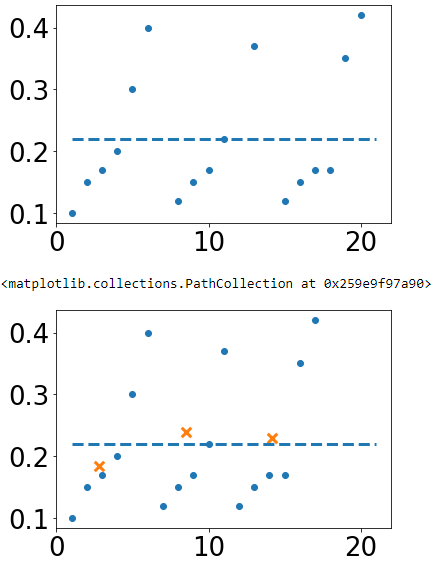
when binned means are plotted together with a data, you could see that the calculation is not matching (which make sense). Question 1: Is there a simple-general solution to perform a binned mean ignoring nan values?
A few notes:
- here there's a binning algorithm that has a
nanHandling : Noneoption
‘ignore’: In this case, NaNs contained in the input data are removed from the data prior binning. Note however, that x0, unless specified explicitly, will still refer to the first data point, whether or not this holds a NaN value.
- Also there's an issue reported in GitHub: "scipy.stats.binned_statistic regressed in v1.4.0 #11365" in which
barentsenreports that
PR #10664 recently changed the behavior of scipy.stats.binned_statistic to raise a ValueError whenever the data contains a non-finite number (e.g.,
nan,inf). This new behavior is counter-intuitive because many other statistical methods do not raise exceptions in the presence of NaNs, e.g.np.mean([np.nan])returnsnanrather than raising an exception.
and
(...) A user could choose to ignore the NaNs by providing a custom statistic function, e.g.
np.nanmean:
>>> import scipy.stats, numpy as np
>>> x = [0.5, 0.5, 1.5, 1.5]
>>> values = [10, 20, np.nan, 40]
>>> scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
As of
SciPy v1.4.0, the examples above raise thisValueError
>>> scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/gb/bin/anaconda/envs/sp14/lib/python3.7/site-packages/scipy/stats/_binned_statistic.py", line 180, in binned_statistic
[x], values, statistic, bins, range)
File "/home/gb/bin/anaconda/envs/sp14/lib/python3.7/site-packages/scipy/stats/_binned_statistic.py", line 519, in binned_statistic_dd
raise ValueError('%r or %r contains non-finite values.' % (sample, values,))
ValueError: [[0.5, 0.5, 1.5, 1.5]] or [10, 20, nan, 40] contains non-finite values.
Question 2: is there a simple way to use statistic=np.nanmean ?
CodePudding user response:
The answer to both questions 1 and 2 is to use np.nanmean to ignore the nans in the data. The regression you link to was a bug that I inadvertently introduced and then fixed after it was raised. I'm not sure why you have SciPy 1.5.2 in your environment, it looks like 1.5.4 is the latest 1.5.X version so you probably want to update the environment you're using. However, that backport was applied to version 1.5.0 release versions so there should not be an issue on those versions if you have the latest.
Also, I set this up with scipy version 1.7.3 and that also works as intended for me. Here are snippets.
Version 1.5.4
import scipy
scipy.__version__
'1.5.4'
import numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
Version 1.7.3
import scipy
scipy.__version__
'1.7.3'
import scipy.stats, numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
Version 1.5.2
import scipy
scipy.__version__
'1.5.2'
import scipy.stats, numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
Please try using the .__version__ to confirm your version of SciPy. If it is a 1.4.1 version-it does not have the change. I suspect that your version is 1.4.1 and not the other (higher) versions. Please use the portions of the code examples above to confirm the scipy version that is used in your environment.