I have a list of lists, each sublist of the list contains keywords to filter text from a dataframe.
keywords = [[('tarifa',), ('mantenimiento',), ('mensual',)],
[('tasa',), ('anual',)],
[('seguro',), ('bancaria',)],
[('seguro',), ('generales',)],
[('mi salud',), ('unific',)]]
I used to filter by typing the keywords manually like this:
#for sublist 1:
kw_s = kw_df[kw_df['transaction_description'].str.contains('tarifa') & kw_df['transaction_description'].str.contains('mantenimiento') & kw_df['transaction_description'].str.contains('mensual')]
#for sublist 2:
kw_s = kw_df[kw_df['transaction_description'].str.contains('seguro') & kw_df['transaction_description'].str.contains('generales')]
Now I must filter according to the keywords configured in a mysql table. So, I save the keywords in a list of lists, but I don't know how to extract the keywords by sublist to filter the dataframe.
Any idea how I could do it?
Here an example of the dataframe
user_id reg_id date transaction_description value
kw_df = [[5, 56, Timestamp('2022-01-29 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 57, Timestamp('2021-12-19 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 60, Timestamp('2021-04-06 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 178, Timestamp('2022-03-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 179, Timestamp('2022-03-01 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 182, Timestamp('2022-03-15 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 189, Timestamp('2022-04-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 190, Timestamp('2022-04-01 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 193, Timestamp('2022-04-15 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 206, Timestamp('2022-05-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 256, Timestamp('2022-06-17 00:00:00'), 'cargo seguro proteccion bancaria', 40222.0]]
CodePudding user response:
How to filter a DataFrame by a volatile subset of words?
Dummy data
import numpy as np
import pandas as pd
columns = ['transaction_description', 'value']
data = [
['pac c.misalud conv. unificado', 12320.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac c.misalud conv. unificado', 12320.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac c.misalud conv. unificado', 12320.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['cargo seguro proteccion bancaria', 40222.0]]
df=pd.DataFrame(data, columns=columns)
keywords = [
[('tarifa',), ('mantenimiento',), ('mensual',)],
[('tasa',), ('anual',)],
[('seguro',), ('bancaria',)],
[('seguro',), ('generales',)],
[('mi salud',), ('unific',)]]
Solving
I will use a structure where the words of the sublists are arranged in columns, or to be precise, each word is placed in the list as the only element of a tuple.
Let's vectorize str.__contains__ to make the str1 in str2 code applicable to arrays:
contains = np.vectorize(str.__contains__)
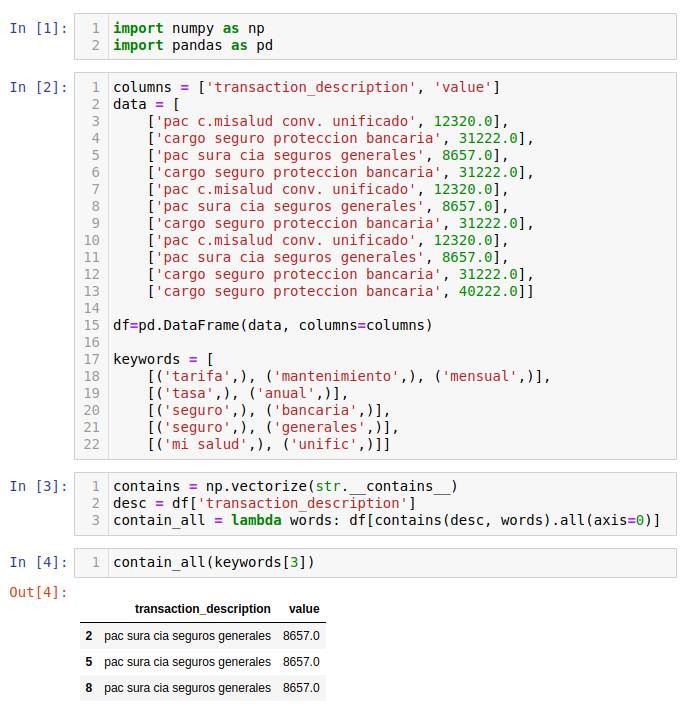
Now, I'll test this function on df["transaction_description"] and the 4th set of keywords [('seguro',), ('generales',)] for example:
desc = df['transaction_description']
contains(desc, keywords[3])
In this case, we get the following result:
array([[False, True, True, True, False, True, True, False, True, True, True],
[False, False, True, False, False, True, False, False, True, False, False]])
Now, to see if all words of this subset can be found in a description, we apply the method all along the first index of the previous matrix:
df[contains(desc, keywords[3]).all(axis=0)]
And we obtain these filtered data:
transaction_description value
2 pac sura cia seguros generales 8657.0
5 pac sura cia seguros generales 8657.0
8 pac sura cia seguros generales 8657.0
Long story short
contains = np.vectorize(str.__contains__)
desc = df['transaction_description']
contain_all = lambda words: df[contains(desc, words).all(axis=0)]