Here is part of my data:
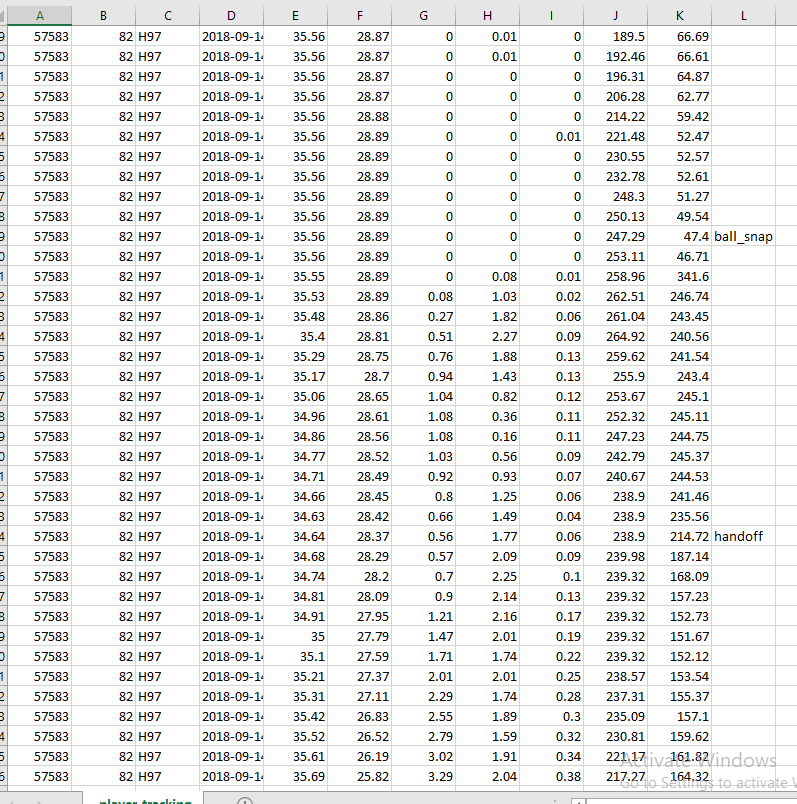
I want to create a dataframe with every row after the row with L = ball_snap in it. So not only that specific row but every row after it as well.
How would I do that in pandas?
CodePudding user response:
You can use idxmax to return the row with L = ball_snap and use the slice notation to extract all rows after:
df1 = df.loc[df['L'].eq('ball_snap').idxmax():]
Input:
>>> df
A B C L
0 8 6 9
1 3 1 6
2 4 9 9
3 1 5 1 ball_snap
4 3 7 0
5 9 2 0
6 1 8 4
7 7 9 8
8 5 9 1
9 4 3 4
Output:
>>> df1
A B C L
3 1 5 1 ball_snap
4 3 7 0
5 9 2 0
6 1 8 4
7 7 9 8
8 5 9 1
9 4 3 4
Update: if you don't want the row with 'ball_snap' use shift before idxmax:
df2 = df.loc[df['L'].eq('ball_snap').shift(fill_value=False).idxmax():]
Output:
>>> df2
A B C L
4 3 7 0
5 9 2 0
6 1 8 4
7 7 9 8
8 5 9 1
9 4 3 4
CodePudding user response:
To select every row after a given index and/or including that index, you can use a Dataframe's tail method with a negative value, for example:
idx_first_ball_snap = df.index[df['L'] == 'ball_snap'].tolist()[0]
print(df.tail(-idx_first_ball_snap))
This selects the first row with "ball_snap" and also every row afterwards:
K L
2 47.40 ball_snap
3 46.71
4 341.60
5 246.74
.
.
.
etc
Here's the documentation on DataFrame method tail: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.tail.html
CodePudding user response:
Here is another way using cummax()
df.loc[df['L'].eq('ball_snap').cummax()]
Output:
A B C L
3 1 5 1 ball_snap
4 3 7 0 NaN
5 9 2 0 NaN
6 1 8 4 NaN
7 7 9 8 NaN
8 5 9 1 NaN
9 4 3 4 NaN