I have a data like this
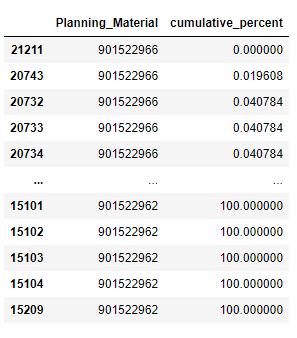
I want to segment/ filter the data into A, B, C buckets based on the column cumulative_percent and condition 0 - ~ 80% of cumulative_percent needs to be in bucket A, ~80 - ~95% in bucket B and ~95% - 100% in bucket C. The problem I'm facing is I dont want to divide materials into two different buckets while creating this filter, I want to filter in the closest percent(whether greater than or lesser than 80% doesn't matter) .
For example,
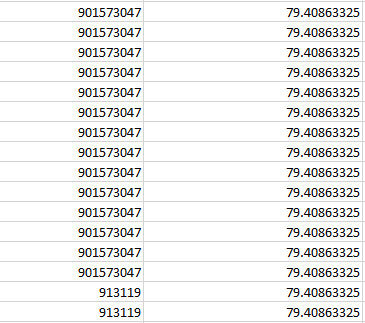
if I add a filter like
if cumulative_percent <= 79.4086332486936 :
return 'A'
This would add Material No 901573047 and 913119 in Bucket A, but the rest of material 913119 might have a cumulative_percent of 80.00023232
CodePudding user response:
I would suggest using some reproducible code rather than posting an image as they are not very helpful (see here).
You can filter a DataFrame based on a condition using loc in pandas.
So assuming your DataFrame is called df
df = df.loc[df['cumulative_percent'] < 80, 'Bucket'] = 'A'
df = df.loc[(df['cumulative_percent'] >= 80) & (df['cumulative_percent'] < 95), 'Bucket'] = 'B'
df = df.loc[df['cumulative_percent'] >= 95, 'Bucket'] = 'C'
From there you now have a new column for each of the newly categorized rows.
If you are saying that there are rows were the value of cumulative_percent is not correct or does not match other Material No then you would need create a rule to account for how to deal with incorrect values.
If you just want to say for each Material No use the minimum cumulative_percent you could do that something like this:
df['new_cumulative_percent'] = df.groupby('Planning_Material')['cumulative_percent'].transform('min')
And then just filter on the new "corrected" cumulative_percent values
CodePudding user response:
You can use pd.cut to create categories:
df['bucket'] = pd.cut(df['cumulative_percent'], [0, 80, 95, 100], labels=['A', 'B', 'C'])
print(df)
# Output
cumulative_percent bucket
0 0.477769 A
1 1.019964 A
2 1.582226 A
3 1.808495 A
4 2.450631 A
.. ... ...
195 100.000000 C
196 100.000000 C
197 100.000000 C
198 100.000000 C
199 100.000000 C
[200 rows x 2 columns]