basically trying to do some data cleaning in Jupyter Notebook and i am not the best with the syntax so have reached a roadblock. I have a column at the end with mean and if the mean is 0, i would like to delete that row as well as another row which is either above or below that has the same 'Customer' and 'Date' column values.
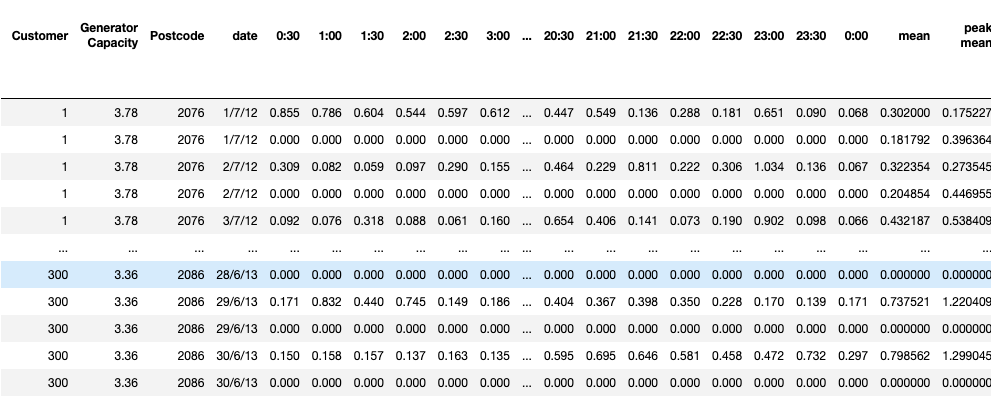
So far i am trying something across these lines but with little success where both_index is my variable name for the DataFrame
for i in both_index['peak mean']: #this is part of code below
if i == 0:
for j in both_index['peak mean']:
if both_index['Customer'][i] == both_index['Customer'][j]: #this is wrong and i dont know the syntax
both_index.drop(j)
both_index.drop(i)
Any help would be appreciated thank you!
CodePudding user response:
I'm not too familiar with pandas or jupyter, but I found another question with an answer that looks promising. It mentioned a way to drop rows with a condition like this:
DF.drop(DF[DF.LABEL CONDITION].index, inplace=True)
In your case, it would look like this:
both_index.drop(both_index[df['peak mean'] == 0].index, inplace=True)
Backup your data if you can before trying this.
EDIT: Just noticed that this answer isn't complete. Won't delete the extra rows with the same 'Customer' and 'Date'
CodePudding user response:
both_index = both_index.set_index(['Customer', 'date'])
df1 = both_index[both_index['peak mean'] == 0]
both_index = both_index.loc[~both_index.index.isin(df1.index)]
CodePudding user response:
You could try this:
df = pd.DataFrame({'Customer': ['#1','#1','#1','#2','#2','#3','#3'], 'Date': [1,1,2,2,2,3,3], 'peak mean': [1,0,2,2,3,0,4]})'peak mean': [1,0,2,2,3,0,4]})
df = df.set_index(['Customer', 'Date']) #do not miss this important step!
print(df)
peak mean
Customer Date
#1 1 1 #to delete
#1 1 0 #to delete
#1 2 2
#2 2 2
#2 2 3
#3 3 0 #to delete
#3 3 4 #to delete
In this example, we expect to keep only 1 row of customer #1, and also both rows of customer #2
df1 = df.drop(df.loc[df['peak mean']==0].index)
print(df1)
peak mean
Customer Date
#1 2 2
#2 2 2
#2 2 3