I have a 3d scatterplot, with variables A,B,C. I want to highlight the quadrant of the plot where the points are higher than the average for A,B and C.
Currently, I have a scatter plot with lines where the averages are for each variable. The red line is the average of B, the blue is the average of A. Both lines are at the height of the average of C.
So the important points are behind the red line, in front of the blue and above both lines. I'm not sure if that is an intuitive way of displaying the data. I was thinking that I could add a plain to this region to highlight it, but I'm not sure of how to do that.
Also I need to add labels to the points, I'm not sure how to do this either. I'm assuming it is supposed to be something like this
for i in range(len(df)):
x = m[i,0]
y = m[i,1]
z = m[i,2]
label = i
ax.scatter(x,y,z, color='b')
ax.text(x,y,z, '%s' % (label), size=20, zorder=1, color='k')
but I don't know how this works so I'm not sure how to adapt this to what I need.
My full code is as follows;
import numpy as np
import pandas as pd
import random
import string
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Sample Dataframe
names=[]
df = pd.DataFrame(np.random.randint(0,200,size=(200, 3)), columns=list('ABC'))
for item in df['A']:
names.append(random.choice(string.ascii_letters))
df['name']=names
df.head(2)
# Plotting
plt.rcParams["figure.figsize"] = (20,10)
x = df['A']
y = df['B']
z = df['C']
# create the figure
fig = plt.figure()
# add axes
ax = fig.add_subplot(111,projection='3d')
ax.scatter(x,y,z, s=60)
# make lines
xline = [(df['A'].max(),0), (df['B'].mean(),df['B'].mean()),(df['C'].mean(),df['C'].mean())]
ax.plot(xline[0], xline[1], xline[2], 'r')
yline = [(df['A'].mean(),df['A'].mean()), (df['B'].max(),0),(df['C'].mean(),df['C'].mean())]
ax.plot(yline[0], yline[1], yline[2], 'b')
# label the axes
ax.set_xlabel("A")
ax.set_ylabel("B")
ax.set_zlabel("C")
plt.show()
CodePudding user response:
I would suggest getting rid of the lines and instead filtering the data into an "important" and a "less important" set. Then both can be plotted separatly, with different colors and/or sizes.
I habe included a labeling approach for this filtered dataset as well.
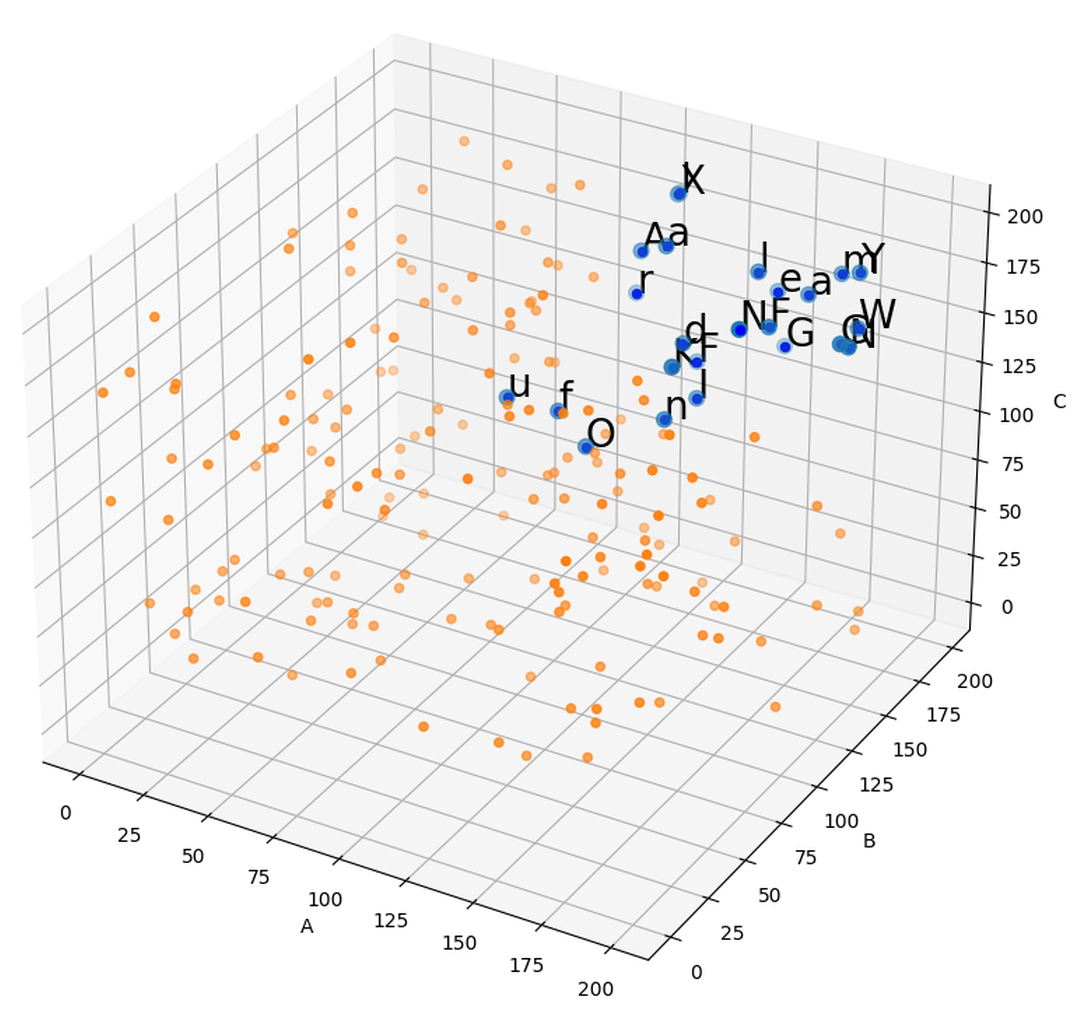
import random
import string
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Sample Dataframe
names=[]
df = pd.DataFrame(np.random.randint(0,200,size=(200, 3)), columns=list('ABC'))
for item in df['A']:
names.append(random.choice(string.ascii_letters))
df['name']=names
df.head(2)
filter = (
(df['A'] > df['A'].mean()) &
(df['B'] > df['B'].mean()) &
(df['C'] > df['C'].mean())
)
# Plotting
plt.rcParams["figure.figsize"] = (20,10)
x = df[filter]['A']
y = df[filter]['B']
z = df[filter]['C']
x_less_important = df[~filter]['A']
y_less_important = df[~filter]['B']
z_less_important = df[~filter]['C']
# create the figure
fig = plt.figure()
# add axes
ax = fig.add_subplot(111,projection='3d')
ax.scatter(x,y,z, s=60)
ax.scatter(x_less_important,y_less_important,z_less_important, s=20)
# label the axes
ax.set_xlabel("A")
ax.set_ylabel("B")
ax.set_zlabel("C")
# label the points
for i in range(len(x)):
label = df['name'].iloc[i]
ax.scatter(x.iloc[i],y.iloc[i],z.iloc[i], color='b')
ax.text(x.iloc[i],y.iloc[i],z.iloc[i], '%s' % (label), size=20, zorder=1, color='k')
plt.show()