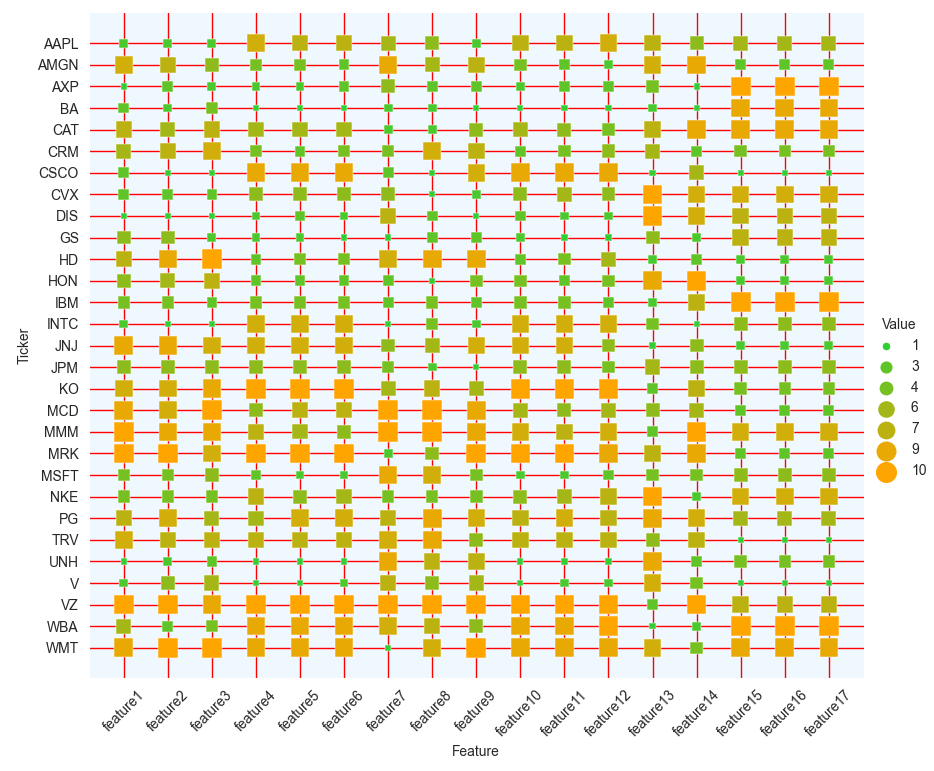
Suppose I have a heatmap plot like this:
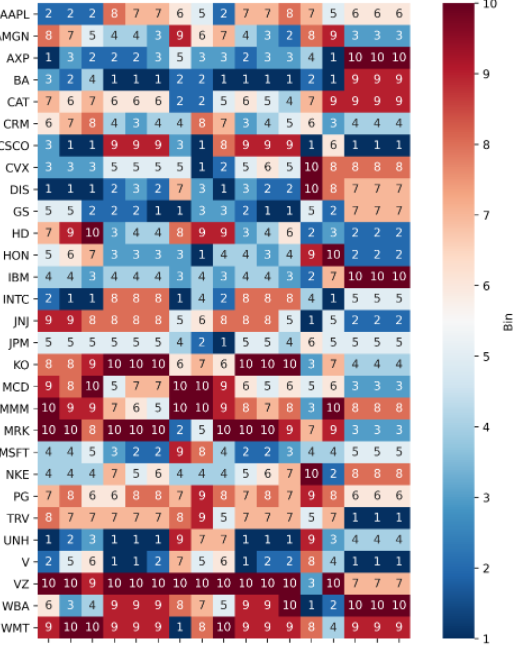
Using this data:
import numpy as np
import pandas as pd
arr = np.array([[ 2, 2, 2, 8, 7, 7, 6, 5, 2, 7, 7, 8, 7, 5, 6, 6, 6],
[ 8, 7, 5, 4, 4, 3, 9, 6, 7, 4, 3, 2, 8, 9, 3, 3, 3],
[ 1, 3, 2, 2, 2, 3, 5, 3, 3, 2, 3, 3, 4, 1, 10, 10, 10],
[ 3, 2, 4, 1, 1, 1, 2, 2, 1, 1, 1, 1, 2, 1, 9, 9, 9],
[ 7, 6, 7, 6, 6, 6, 2, 2, 5, 6, 5, 4, 7, 9, 9, 9, 9],
[ 6, 7, 8, 4, 3, 4, 4, 8, 7, 3, 4, 5, 6, 3, 4, 4, 4],
[ 3, 1, 1, 9, 9, 9, 3, 1, 8, 9, 9, 9, 1, 6, 1, 1, 1],
[ 3, 3, 3, 5, 5, 5, 5, 1, 2, 5, 6, 5, 10, 8, 8, 8, 8],
[ 1, 1, 1, 2, 3, 2, 7, 3, 1, 3, 2, 2, 10, 8, 7, 7, 7],
[ 5, 5, 2, 2, 2, 1, 1, 3, 3, 2, 1, 1, 5, 2, 7, 7, 7],
[ 7, 9, 10, 3, 4, 4, 8, 9, 9, 3, 4, 6, 2, 3, 2, 2, 2],
[ 5, 6, 7, 3, 3, 3, 3, 1, 4, 4, 3, 4, 9, 10, 2, 2, 2],
[ 4, 4, 3, 4, 4, 4, 3, 4, 3, 4, 4, 3, 2, 7, 10, 10, 10],
[ 2, 1, 1, 8, 8, 8, 1, 4, 2, 8, 8, 8, 4, 1, 5, 5, 5],
[ 9, 9, 8, 8, 8, 8, 5, 6, 8, 8, 8, 5, 1, 5, 2, 2, 2],
[ 5, 5, 5, 5, 5, 5, 4, 2, 1, 5, 5, 4, 6, 5, 5, 5, 5],
[ 8, 8, 9, 10, 10, 10, 6, 7, 6, 10, 10, 10, 3, 7, 4, 4, 4],
[ 9, 8, 10, 5, 7, 7, 10, 10, 9, 6, 5, 6, 5, 6, 3, 3, 3],
[10, 9, 9, 7, 6, 5, 10, 10, 9, 8, 7, 8, 3, 10, 8, 8, 8],
[10, 10, 8, 10, 10, 10, 2, 5, 10, 10, 10, 9, 7, 9, 3, 3, 3],
[ 4, 4, 5, 3, 2, 2, 9, 8, 4, 2, 2, 3, 4, 4, 5, 5, 5],
[ 4, 4, 4, 7, 5, 6, 4, 4, 4, 5, 6, 7, 10, 2, 8, 8, 8],
[ 7, 8, 6, 6, 8, 8, 7, 9, 8, 7, 8, 7, 9, 8, 6, 6, 6],
[ 8, 7, 7, 7, 7, 7, 8, 9, 5, 7, 7, 7, 5, 7, 1, 1, 1],
[ 1, 2, 3, 1, 1, 1, 9, 7, 7, 1, 1, 1, 9, 3, 4, 4, 4],
[ 2, 5, 6, 1, 1, 2, 7, 5, 6, 1, 2, 2, 8, 4, 1, 1, 1],
[10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 3, 10, 7, 7, 7],
[ 6, 3, 4, 9, 9, 9, 8, 7, 5, 9, 9, 10, 1, 2, 10, 10, 10],
[ 9, 10, 10, 9, 9, 9, 1, 8, 10, 9, 9, 9, 8, 4, 9, 9, 9]])
columns = ["feature1", "feature2", "feature3", "feature4", "feature5", "feature6", "feature7", "feature8", "feature9", "feature10", "feature11", "feature12", "feature13", "feature14", "feature15", "feature16", "feature17"]
indexes = ['AAPL', 'AMGN', 'AXP', 'BA', 'CAT', 'CRM', 'CSCO', 'CVX', 'DIS', 'GS',
'HD', 'HON', 'IBM', 'INTC', 'JNJ', 'JPM', 'KO', 'MCD', 'MMM', 'MRK',
'MSFT', 'NKE', 'PG', 'TRV', 'UNH', 'V', 'VZ', 'WBA', 'WMT']
df = pd.DataFrame(arr, columns=columns, index=indexes)
Using this code:
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,10), dpi=600)
a = sns.heatmap(df, annot=True, cmap="RdBu_r", square=True, ax=ax)
plt.show()
I want to adjust each cell's size based on its value! I mean, the square cells with the value of 1 should be smaller than those with higher values!
Example:
Note that this example is not strictly related to the values of the previous heatmap plot! I just provided an example to show what I mean by adjusting each square cell size based on its value.
CodePudding user response:
This is something you can accomplish with scatterplot or relplot:
flights = sns.load_dataset("flights")
g = sns.relplot(
data=flights,
x="year", y="month", size="passengers", hue="passengers",
marker="s", sizes=(40, 400), palette="blend:b,r",
)
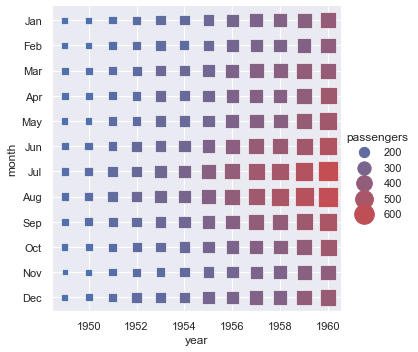
CodePudding user response:
(This post elaborates on @mwaskom's excellent solution, adapted to the given dataframe.)
For most seaborn functions, it helps to have the dataframe in