I am working on a SQL grammar where pretty much anything can be an expression, even places where you might not realize it. Here are a few examples:
-- using an expression on the list indexing
SELECT ([1,2,3])[(select 1) : (select 1 union select 1 limit 1)];

Of course this is an extreme example, but my point being, many places in SQL you can use an arbitrarily nested expression (even when it would seem "Oh that is probably just going to allow a number or string constant).
Because of this, I currently have one long rule for expressions that may reference itself, the following being a pared down example:
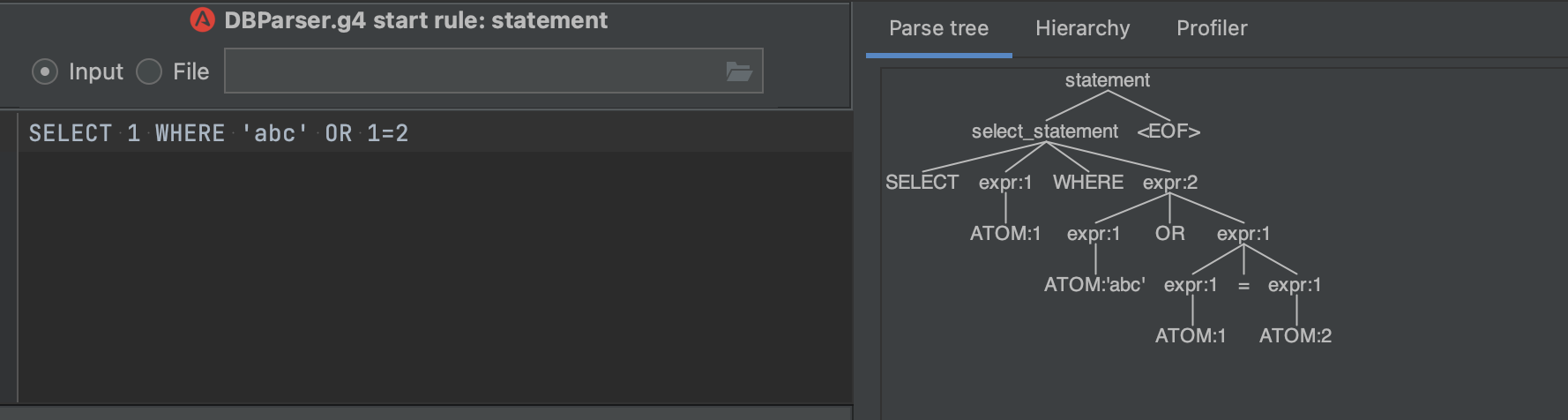
grammar DBParser;
options { caseInsensitive=true; }
statement:select_statement EOF;
select_statement
: 'SELECT' expr
'WHERE' expr // The WHERE clause should only allow a BoolExpr
;
expr
: expr '=' expr # EqualsExpr
| expr 'OR' expr # BoolExpr
| ATOM # ConstExpr
;
ATOM: [0-9] | '\'' [a-z] '\'';
WHITESPACE: [ \t\r\n] -> skip;
With sample input SELECT 1 WHERE 'abc' OR 1=2. However, one place I do want to limit what expressions are allowed is in the WHERE (and HAVING) clause, where the expression must be a boolean expression, in other words WHERE 1=1 is valid, but WHERE 'abc' is invalid. In practical terms what this means is the top node of the expression must be a BoolExpr. Is this something that I should modify in my parser rules, or should I be doing this validation downstream, for example in the semantic phase of validation? Doing it this way would probably be quite a bit simpler (even if the lexer rules are a bit lax), as there would be so much indirection and probably indirect left-recursion involved that it would become incredibly convoluted. What would be a good approach here?
CodePudding user response:
Your intuition is correct that breaking this out would probably create indirect left recursion. Also, is it possible that an IDENTIFIER could represent a boolean value?
This is the point of @user207421's comment. You can't fully capture types (i.e. whether an expression is boolean or not) in the parser.
The parser's job (in the Lexer & Parser sense), put fairly simply, is to convert your input stream of characters into the a parse tree that you can work with. As long as it gives a parse tree that is the only possible way to interest the input (whether it is semantically valid or not), it has served its purpose. Once you have a parse tree then during semantic validation, you can consider the expression passed as a parameter to your where clause and determine whether or not it has a boolean value (this may even require consulting a symbol table to determine the type of an identifier). Just like your semantic validation of an OR expression will need to determine that both the lhs and rhs are, themselves, boolean expressions.
Also consider that even if you could torture the parser into catching some of your type exceptions, the error messages you produce from semantic validation are almost guaranteed to be more useful than the generated syntax errors. The parser only catches syntax errors, and it should probably feel a bit "odd" to consider a non-boolean expression to be a "syntax error".