Is it possible to handle the same lexical token differently depending on context? The docs says there are 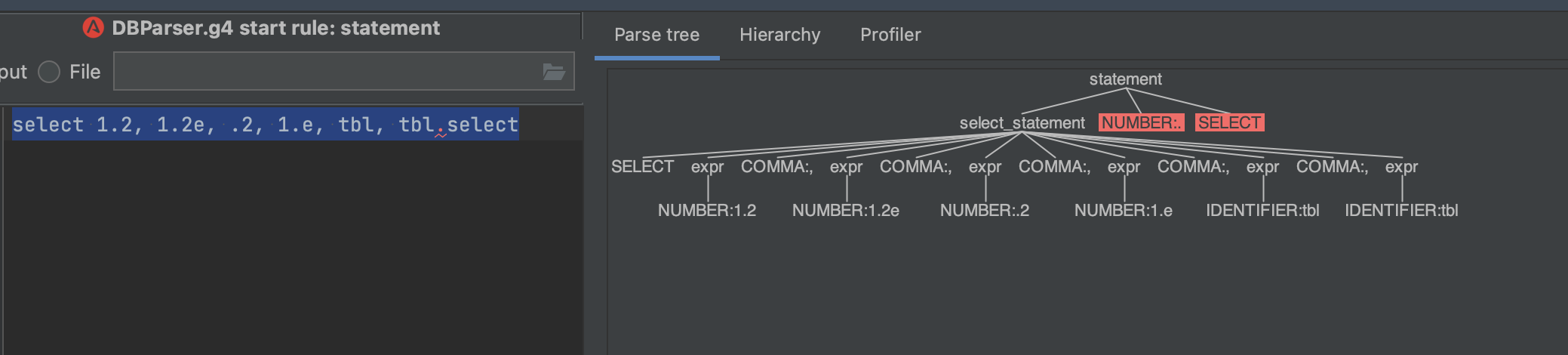
CodePudding user response:
The lexer runs independently of the parser, and parser context cannot influence the lexer (tokenization).
Taking into account your additional example you could do something like the following (a common way of handling anywhere keywords may be allowed but not treated as keywords). (NOTE: I had to add a STRING rule so that the select inside the string wouldn't be recognized as a SELECT token, but that seems a reasonable assumption. It also doesn't parse your example due to the lack of rule for '(' '[' and ':', etc. but I did not take the liberty of attempting to substitute them.
grammar DBParser;
options { caseInsensitive=true; }
statement:select_statement EOF;
select_statement
: SELECT expr (COMMA expr)*
;
expr
: NUMBER
| IDENTIFIER
| STRING
| expr '.' (IDENTIFIER | keyword)
;
keyword
: SELECT
// | ...
;
COMMA: ',';
// 1. Pick up numbers first (simplified number format for question)
NUMBER: [0-9]* '.' [0-9]* 'e'?;
// 2. Reserved Keyword section
SELECT: 'SELECT';
// 3. And if it's not a reserved keyword, pick it up as an identifier
IDENTIFIER: [A-Z_] [A-Z_0-9]*;
STRING: '\'' ~[']* '\'';
WHITESPACE: [ \t\r\n] -> skip;
Also note that the skip on whitespace allows for select ([{'select': 1}])[0] . select; to also be valid. Whether or not that is correct I don't really know, but I suspect it would be desirable in order to break statements across multiple lines.
Just my humble opinion, but I think you'll find that trying to switch lexical modes based on the '.' will not prove productive.
CodePudding user response:
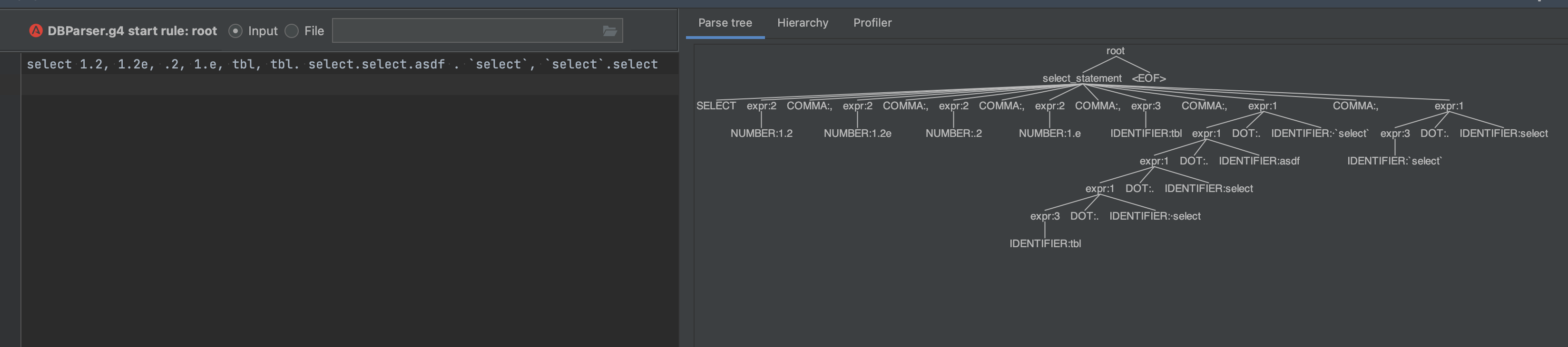
Thanks to Mike for the suggestion on how to push the special mode's token back into the normal IDENTIFIER token. Here is a working example with both quoted and normal identifiers:
parser grammar DBParser;
options { tokenVocab = DBLexer;}
root
: select_statement EOF
;
select_statement
: SELECT expr (COMMA expr)*
;
expr
: expr '.' IDENTIFIER
| NUMBER
| IDENTIFIER
;
lexer grammar DBLexer;
options { caseInsensitive=true; }
// Default mode
DOT : '.' -> mode(PATH_MODE) ;
COMMA: ',';
NUMBER: [0-9]* '.' [0-9]* 'e'?;
SELECT: 'SELECT';
IDENTIFIER: [A-Z_] [A-Z_0-9]* | BQuoteQuoteEscape ;
WS : [ \r\t\n] -> skip ;
fragment BQuoteQuoteEscape: '`' ~[`]*('``' ~[`]*)* '`';
// Special dot-identifier mode only
mode PATH_MODE;
Identifier: [ \r\t\n]* ([a-z_][a-z0-9_] | BQuoteQuoteEscape) -> type(IDENTIFIER), mode(DEFAULT_MODE);
And with input:
select 1.2, 1.2e, .2, 1.e, tbl, tbl. select.select.asdf . `select`, `select`.select
We get: