I want convert the image in to data frame. I am able to read the image and make it a character object.
library(tesseract)
eng1 <- tesseract("eng")
text1 <- tesseract::ocr("image.png", engine = eng1)
cat(text1)
class(text1) #character
head(text1)
[1] "* teamiD ~ yearlD ~~ NumsP_ TGS oplayerID Gx GS Wx > Lx ERAX\n\n1 ANA 1997 11162 finlecnot 12 23 ca 8 452\n2 ANA 1997 11162 langsma0t 162 2 ae 8 452\n3 ANA 1997 11162 perismant 162 8 ae 8 452\n4 ANA 1997 11162 cieksja01 162 32 ae 8 452\n5 ANA 1997 11162 hasegshot 162 7 ae 8 452\n6 ANA 1997 11162 sprindeot 162 8 ae 8 452\n7 ANA 1997 11162, mayda02 162 2 ae 8 452\n8 ANA 1997 1162 ilkeot 12 2 ae 8 452\n9 ANA 1997 11162 grosskeot 162 3 ae 8 452\n10 ANA 1997 11162 gubiemao1 162 2 ae 8 452\n11 ANA 1997 11162 watsoalot 12 Be ae 8 452\n12 ANA 1998 2162 sparksto 162 2 8 7 449\n13, ANA 1998 9 162 cicksja0t 162 18 8 7 449\n14. ANA 1998 9162 alivaomot 12 26 85 7 449\n15. ANA 1998 9162 finlecnot 12 Be 85 7 449\n16 ANA 1998 9162 washbja0t 162 1\" 8 7 449\n47 ANA 1998 9162 watsoalot 12 4 85 7 449\n18 ANA 1998 9162 medowja0t 162 14 8 7 449\n"
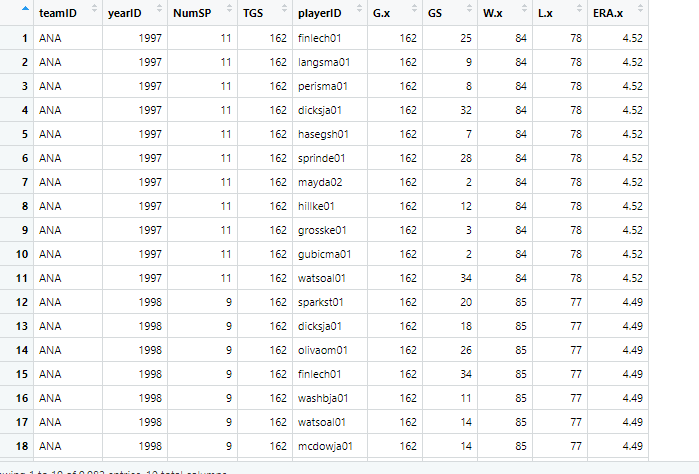
I need the data in data frame that this image show.
CodePudding user response:
Your ocr is not a faithful representation of your image, and you risk garbage in/garbage out, but text1 can be sequentially cleaned to eventually be in a data.frame:
text1_a <- gsub('[[:punct:]]', '', text1)
test1_b <- gsub('(11)', '\\1 ', text1_a)
test1_c <- gsub('(91{1})', '\\1 ', test1_b)
test1_d <- gsub('(21{1})', '\\1 ', test1_c)
read.table(text=test1_d, col.names=c('teamID', 'yearID', 'NumSP', 'TGS','playerID', 'G.x', 'GS', 'W.x', 'L.x', 'ERA.x'))
teamID yearID NumSP TGS playerID G.x GS W.x L.x ERA.x
1 ANA 1997 11 162 finlecnot 12 23 ca 8 452
2 ANA 1997 11 162 langsma0t 162 2 ae 8 452
3 ANA 1997 11 162 perismant 162 8 ae 8 452
4 ANA 1997 11 162 cieksja01 162 32 ae 8 452
5 ANA 1997 11 162 hasegshot 162 7 ae 8 452
6 ANA 1997 11 162 sprindeot 162 8 ae 8 452
7 ANA 1997 11 162 mayda02 162 2 ae 8 452
8 ANA 1997 11 62 ilkeot 12 2 ae 8 452
9 ANA 1997 11 162 grosskeot 162 3 ae 8 452
10 ANA 1997 11 162 gubiemao1 162 2 ae 8 452
11 ANA 1997 11 162 watsoalot 12 Be ae 8 452
12 ANA 1998 21 62 sparksto 162 2 8 7 449
13 ANA 1998 9 162 cicksja0t 162 18 8 7 449
14 ANA 1998 91 62 alivaomot 12 26 85 7 449
15 ANA 1998 91 62 finlecnot 12 Be 85 7 449
16 ANA 1998 91 62 washbja0t 162 1 8 7 449
47 ANA 1998 91 62 watsoalot 12 4 85 7 449
18 ANA 1998 91 62 medowja0t 162 14 8 7 449
The main challenge here is to arrive at consistent number of columns per row, and much of the ocr garbage remains, with a little more added in, but is a data.frame.