I'd like to replace outliers by np.nan. I have a dataframe containing floats, int and NaNs such as:
df_ex = pd.DataFrame({
'a': [np.nan,np.nan,2.0,-0.5,6,120],
'b': [1, 3, 4, 2,40,11],
'c': [np.nan, 2, 3, 4,2,2],
'd': [6, 2.2, np.nan, 0,3,3],
'e': [12, 4, np.nan, -5,5,5],
'f': [2, 3, 8, 2,12,8],
'g': [3, 3, 9.0, 11, np.nan,2]})
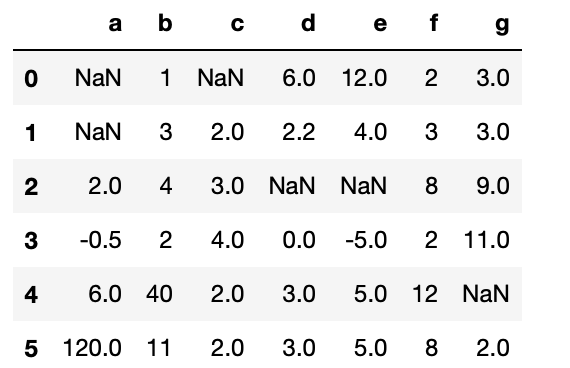
with this function:
def outliers(s, replace=np.nan):
Q1, Q3 = np.percentile(s, [25 ,75])
IQR = Q3-Q1
return s.where((s >= (Q1 - 1.5 * IQR)) & (s <= (Q3 1.5 * IQR)), replace)
df_ex_o = df_ex.apply(outliers, axis=1)
but I get:
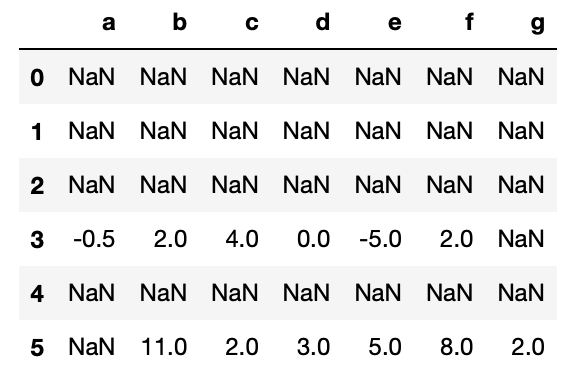
Any idea on what's going on? I'd like the outliers to be calculated column wise.
Thanks as always for your help.
CodePudding user response:
Don't use apply here is the annotated code for the optimized version:
def mask_outliers(df, replace):
# Calculate Q1 and Q2 quantile
q = df.agg('quantile', q=[.25, .75])
# Calculate IQR = Q2 - Q1
iqr = q.loc[.75] - q.loc[.25]
# Calculate lower and upper limits to decide outliers
lower = q.loc[.25] - 1.5 * iqr
upper = q.loc[.75] 1.5 * iqr
# Replace the values that does not lies between [lower, upper]
return df.where(df.ge(lower) & df.le(upper), replace)
Result
mask_outliers(df_ex, np.nan)
a b c d e f g
0 NaN 1.0 NaN NaN NaN 2 3.0
1 NaN 3.0 2.0 2.2 4.0 3 3.0
2 2.0 4.0 3.0 NaN NaN 8 9.0
3 -0.5 2.0 4.0 NaN NaN 2 11.0
4 6.0 NaN 2.0 3.0 5.0 12 NaN
5 NaN 11.0 2.0 3.0 5.0 8 2.0
CodePudding user response:
The only problem with your approach is that you need to remove the NaN values from the column to calculate percentile() as else you will get for both Q1 and Q3 NaN.
Adding a line and changing the other:
colmn_noNaN = colmn.dropna()
Q1, Q3 = np.percentile(colmn_noNaN, [25 ,75])
will solve the problem. Below the entire code and its output:
import pandas as pd
import numpy as np
df_ex = pd.DataFrame({
'a': [np.nan,np.nan,2.0,-0.5,6,120],
'b': [1, 3, 4, 2,40,11],
'c': [np.nan, 2, 3, 4,2,2],
'd': [6, 2.2, np.nan, 0,3,3],
'e': [12, 4, np.nan, -5,5,5],
'f': [2, 3, 8, 2,12,8],
'g': [3, 3, 9.0, 11, np.nan,2]})
# print(df_ex)
def outliers(colmn, replace=np.nan):
colmn_noNaN = colmn.dropna()
Q1, Q3 = np.percentile(colmn_noNaN, [25 ,75])
IQR = Q3-Q1
return colmn.where((colmn >= (Q1 - 1.5 * IQR)) & (colmn <= (Q3 1.5 * IQR)), replace)
df_ex_o = df_ex.apply(outliers, axis = 1)
print(df_ex_o)
gives:
a b c d e f g
0 NaN 1.0 NaN 6.0 12.0 2.0 3.0
1 NaN 3.0 2.0 2.2 NaN 3.0 3.0
2 2.0 4.0 3.0 NaN NaN 8.0 9.0
3 -0.5 2.0 4.0 0.0 -5.0 2.0 NaN
4 6.0 NaN 2.0 3.0 5.0 12.0 NaN
5 NaN 11.0 2.0 3.0 5.0 8.0 2.0