I have a list which looks something like this,
list = ['some random sentence','some random sentence 25% •Assignments for week1',
'some random sentence','some random sentence 20% •Exam for week2','some random sentence',
'some random sentence']
This is extracted from a pdf. I want to take only specific characters and words from a specific value in this list and convert it into pandas dataframe, something like this,
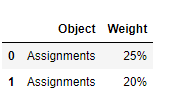
The word 'Assignment' is just an example, there could be different words but always after the percentage sign. It may have multiple spaces or sometimes 1-2 special characters. Is there a way to do this?
CodePudding user response:
With str.extract:
l = ['some random sentence','some random sentence 25% •Assignments for week1',
'some random sentence','some random sentence 20% •Exam for week2','some random sentence',
'some random sentence']
out = (pd.Series(l)
.str.extract(r'(?P<Weight>\d %)\W*(?P<Object>\w )')
.dropna(subset='Object')
)
print(out)
Output:
Weight Object
1 25% Assignments
3 20% Exam
older answer
If you have a single term to match:
l = ['some random sentence','some random sentence 25% •Assignments for week1',
'some random sentence','some random sentence 20% •Assignments for week2','some random sentence',
'some random sentence']
s = pd.Series(l)
m = s.str.contains('assignment', case=False)
out = (s[m].str.extract(r'(?P<Weight>\d %)')
.assign(Object='Assignment')
)
print(out)
Alternative with a regex to match any number of terms:
s = pd.Series(l)
out = (s.str.extractall(r'(?P<Object>Assignment|otherword)|(?P<Weight>\d %)')
.groupby(level=0).first()
)
Output:
Object Weight
1 Assignment 25%
3 Assignment 20%
CodePudding user response:
I think the most simple is using regex :
import re
def regex_split(sentence):
match = re.search(r". (\d )% •(\w ) for week\d", sentence)
if match:
return match.group(1) '%', match.group(2)
else:
return "None"
df = pd.DataFrame({"sentence": list})
df["data"] = df["sentence"].apply(lambda x: regex_split(x))
df = df[df["data"] != "None"]
df["Object"] = df["data"].apply(lambda x: x[0])
df["Weight"] = df["data"].apply(lambda x: x[1])
df.drop(["sentence", "data"], axis=1)