we have the following dataframe .
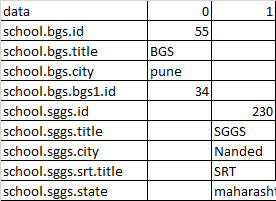
import pandas as pd
import numpy as np
a1 =["school.bgs.id","school.bgs.title","school.bgs.city","school.bgs.bgs1.id","school.sggs.id","school.sggs.title","school.sggs.city","school.sggs.srt.title","school.sggs.state"]
a2=[55,"BGS","pune",34,np.nan,np.nan,np.nan,np.nan,np.nan]
a3=[np.nan,np.nan,np.nan,np.nan,230,"SGGS","Nanded","SRT","maharashtra"]
df =pd.DataFrame(list(zip(a1,a2,a3)),columns=['data',0,1])
and expected output:
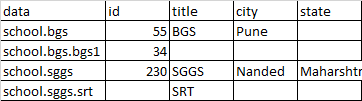
Kindly suggest better solution for the same
CodePudding user response:
This will do what you've asked:
df['new_row'] = df.data.str.split('.').str[:-1].str.join('.')
df['new_col'] = df.data.str.split('.').str[-1]
df['new_val'] = df[0].where(df[0].notna(), df[1])
df = df.pivot('new_row','new_col','new_val')[['id','title','city','state']].rename_axis(None, axis='columns').rename_axis(None, axis='index')
Output:
id title city state
school.bgs 55 BGS pune NaN
school.bgs.bgs1 34 NaN NaN NaN
school.sggs 230 SGGS Nanded maharashtra
school.sggs.srt NaN SRT NaN NaN
Explanation:
- take the final dot-separated token within the
datacolumn asnew_coland the corresponding prefix fromdataasnew_row - take the value of column
0if non-null, else that of column1, asnew_val - use
pivot()to create the desired output, with columns reordered using[['id','title','city','state']]and axis names removed usingrename_axis().
CodePudding user response:
using pivot looks quite suitable, so this solution is very similar with this:
df[['data','col']] = df['data'].str.rsplit('.',1,expand=True)
df = df.assign(val=df[0].combine_first(df[1])).pivot('data','col','val')
and the result is:
col city id state title
data
school.bgs pune 55 NaN BGS
school.bgs.bgs1 NaN 34 NaN NaN
school.sggs Nanded 230 maharashtra SGGS
school.sggs.srt NaN NaN NaN SRT
CodePudding user response:
Another rather similar way is as the following:
import pandas as pd
df[['data', 'cols']] = df['data'].str.extract(r'(?P<data>[\w.] )\.(?P<cols>\w $)')
df = (pd.pivot(df, index = 'data', columns='cols', values=[0, 1])
.stack(level=0)
.droplevel(1))
cols city id state title
data
school.bgs pune 55 NaN BGS
school.bgs.bgs1 NaN 34 NaN NaN
school.sggs Nanded 230 maharashtra SGGS
school.sggs.srt NaN NaN NaN SRT