I have a pandas DataFrame that contains rows. Each row represents a trade that took place on a particular symbol. The first column has the symbol name, and the second column has the time at which the trade took place. The other details about the trade (e.g., price or quantity) are not important to this question. The only stock tickers that will appear in my data frame are AAPL, GOOG, and MSFT. For example, I might have:
df = pd.DataFrame([“AAPL”, “GOOG”, “AAPL”, “MSFT”, “GOOG”], [1, 3, 6, 8, 10])
For instance, this means that a trade took place on AAPL at times t=1 and t=6.
I would like to add three more columns to represent the time since the last AAPL, GOOG, and MSFT trade. It represents the time since the last trade on the symbol, and it’s equal to NaN if there haven’t been any trades on that symbol yet.
In my example above, I’d want to have the new “time since last AAPL trade” column equal to [NaN, 2, 5, 2, 4].
The first entry is NaN because there aren’t any AAPL trades before it. Note that a trade shouldn’t match with itself (i.e., if all timestamps are unique, the resulting column should have all positive values with possibly some number of NaN entries). The second and third entries are equal to 2 and 4 because two time units and four time units have elapsed since the last AAPL trade. Again, note the third entry is 4 and not 0 because the third AAPL shouldn’t match with itself. The other values should be computed similarly.
Does anybody know how I can do this? I know I can find the time since the last AAPL transaction for each row containing AAPL by doing a group-by followed by a diff. However, I’d like to also have the correct entries in other rows as well. Do I need to use merge_asof possibly? Thanks so much.
CodePudding user response:
My input:
df = pd.DataFrame(
["AAPL", "GOOG", "AAPL", "MSFT", "GOOG"],
[1, 3, 6, 8, 10],
columns=["trade"]
)
My solution:
for stock in df.trade.unique():
#compute the distances between actual times and all stock trade times
count = (df.index.values-df.loc[df.trade==stock].index.values.reshape(-1,1)).astype(float)
#remove not-positive distances (cause we want to consider only future times)
count[count<=0] = np.nan
#find the minimum positive distance
count = np.nanmin(count, axis=0)
#save the results
df[stock] = count
It's a bit confusing, but I choose this solution in order to avoid loops (except for cycling the stocks, obviously) that could slow down the computing for large temporal data. If you prefer to use a for loop the solution is very simple so I presume you are looking for something faster.
The output is the following:
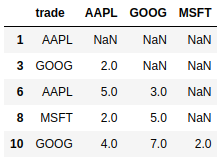
Let me know if you have any doubt.