I'm creating a databricks notebook in pyspark, and I'm trying to create a dynamic json (TSML) to process a cube in analysis service.
In the first part of the code I'm defining the partitions and the fact tables that then independently of the partitions that I place, it dynamically will create a json and is creating well:
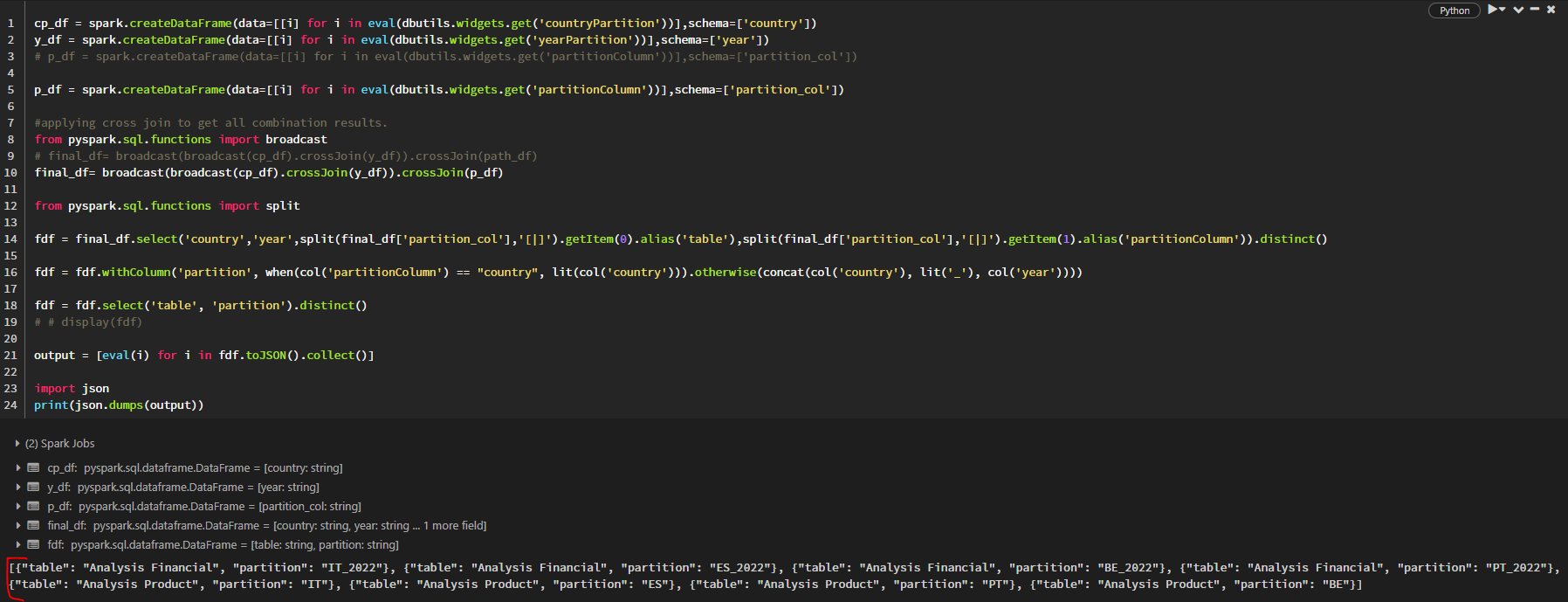
json output 1: {"table": "Analysis Financial", "partition": "IT_2022"}, {"table": "Analysis Financial", "partition": "ES_2022"}, {"table": "Analysis Financial", "partition": "BE_2022"}, {"table": "Analysis Financial", "partition": "PT_2022"}, {"table": "Analysis Product", "partition": "IT"}, {"table": "Analysis Product", "partition": "ES"}, {"table": "Analysis Product", "partition": "PT"}, {"table": "Analysis Product", "partition": "BE"}
Then I want to append with another json that contains the dimension tables, and this part will be static because the tables do not need to dynamically process by partition:
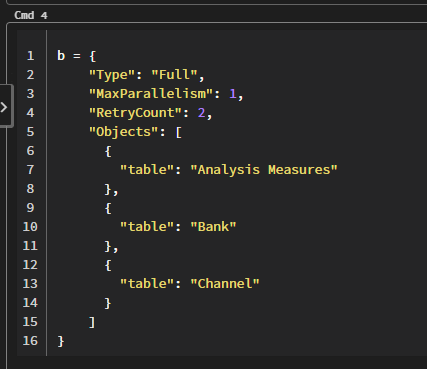
And, to append both I tried this:
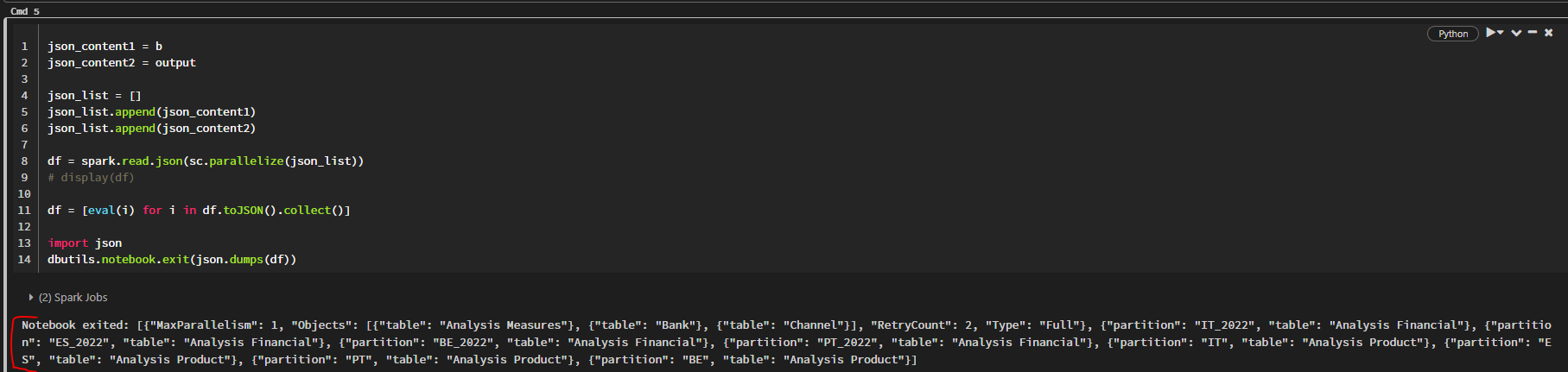
but the output is not correct:
{"MaxParallelism": 1, "Objects": [{"table": "Analysis Measures"}, {"table": "Bank"}, {"table": "Channel"}], "RetryCount": 2, "Type": "Full"}, {"partition": "IT_2022", "table": "Analysis Financial"}, {"partition": "ES_2022", "table": "Analysis Financial"}, {"partition": "BE_2022", "table": "Analysis Financial"}, {"partition": "PT_2022", "table": "Analysis Financial"}, {"partition": "IT", "table": "Analysis Product"}, {"partition": "ES", "table": "Analysis Product"}, {"partition": "PT", "table": "Analysis Product"}, {"partition": "BE", "table": "Analysis Product"}
The output I would want in this case is:
{
"Type":"Full",
"MaxParallelism":1,
"RetryCount":2,
"Objects":[
{
"table":"Analysis Measures"
},
{
"table":"Bank"
},
{
"table":"Channel"
},
{
"table":"Analysis Financial",
"partition":"IT_2022"
},
{
"table":"Analysis Financial",
"partition":"ES_2022"
},
{
"table":"Analysis Financial",
"partition":"BE_2022"
},
{
"table":"Analysis Financial",
"partition":"PT_2022"
},
{
"table":"Analysis Product",
"partition":"IT"
},
{
"table":"Analysis Product",
"partition":"ES"
},
{
"table":"Analysis Product",
"partition":"PT"
},
{
"table":"Analysis Product",
"partition":"BE"
}
]
}
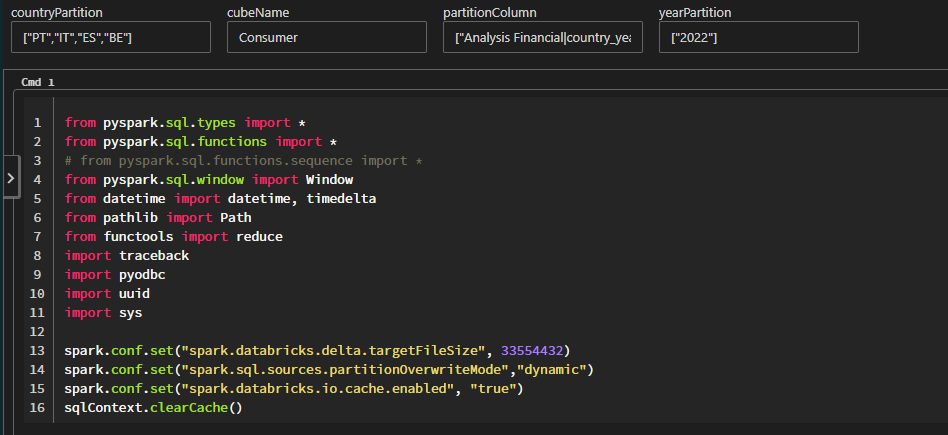
Notebook that I'm using:
# Databricks notebook source
from pyspark.sql.types import *
from pyspark.sql.functions import *
# from pyspark.sql.functions.sequence import *
from pyspark.sql.window import Window
from datetime import datetime, timedelta
from pathlib import Path
from functools import reduce
import traceback
import pyodbc
import uuid
import sys
spark.conf.set("spark.databricks.delta.targetFileSize", 33554432)
spark.conf.set("spark.sql.sources.partitionOverwriteMode","dynamic")
spark.conf.set("spark.databricks.io.cache.enabled", "true")
sqlContext.clearCache()
# COMMAND ----------
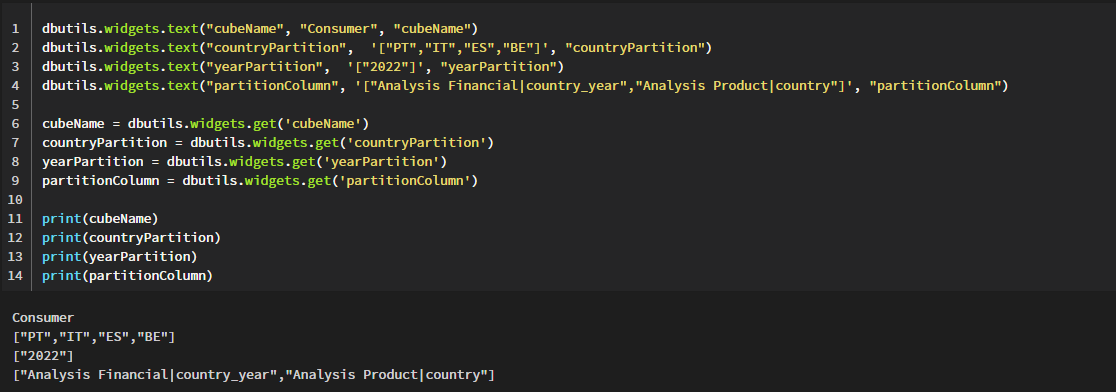
dbutils.widgets.text("cubeName", "Consumer", "cubeName")
dbutils.widgets.text("countryPartition", '["PT","IT","ES","BE"]', "countryPartition")
dbutils.widgets.text("yearPartition", '["2022"]', "yearPartition")
dbutils.widgets.text("partitionColumn", '["Analysis Financial|country_year","Analysis Product|country"]', "partitionColumn")
cubeName = dbutils.widgets.get('cubeName')
countryPartition = dbutils.widgets.get('countryPartition')
yearPartition = dbutils.widgets.get('yearPartition')
partitionColumn = dbutils.widgets.get('partitionColumn')
print(cubeName)
print(countryPartition)
print(yearPartition)
print(partitionColumn)
# COMMAND ----------
cp_df = spark.createDataFrame(data=[[i] for i in eval(dbutils.widgets.get('countryPartition'))],schema=['country'])
y_df = spark.createDataFrame(data=[[i] for i in eval(dbutils.widgets.get('yearPartition'))],schema=['year'])
# p_df = spark.createDataFrame(data=[[i] for i in eval(dbutils.widgets.get('partitionColumn'))],schema=['partition_col'])
p_df = spark.createDataFrame(data=[[i] for i in eval(dbutils.widgets.get('partitionColumn'))],schema=['partition_col'])
#applying cross join to get all combination results.
from pyspark.sql.functions import broadcast
# final_df= broadcast(broadcast(cp_df).crossJoin(y_df)).crossJoin(path_df)
final_df= broadcast(broadcast(cp_df).crossJoin(y_df)).crossJoin(p_df)
from pyspark.sql.functions import split
fdf = final_df.select('country','year',split(final_df['partition_col'],'[|]').getItem(0).alias('table'),split(final_df['partition_col'],'[|]').getItem(1).alias('partitionColumn')).distinct()
fdf = fdf.withColumn('partition', when(col('partitionColumn') == "country", lit(col('country'))).otherwise(concat(col('country'), lit('_'), col('year'))))
fdf = fdf.select('table', 'partition').distinct()
# # display(fdf)
output = [eval(i) for i in fdf.toJSON().collect()]
import json
print(json.dumps(output))
# COMMAND ----------
b = {
"Type": "Full",
"MaxParallelism": 1,
"RetryCount": 2,
"Objects": [
{
"table": "Analysis Measures"
},
{
"table": "Bank"
},
{
"table": "Channel"
}
]
}
# COMMAND ----------
json_content1 = b
json_content2 = output
json_list = []
json_list.append(json_content1)
json_list.append(json_content2)
df = spark.read.json(sc.parallelize(json_list))
# display(df)
df = [eval(i) for i in df.toJSON().collect()]
import json
dbutils.notebook.exit(json.dumps(df))
Can anyone please help me in achieving this?
Thank you!
CodePudding user response:
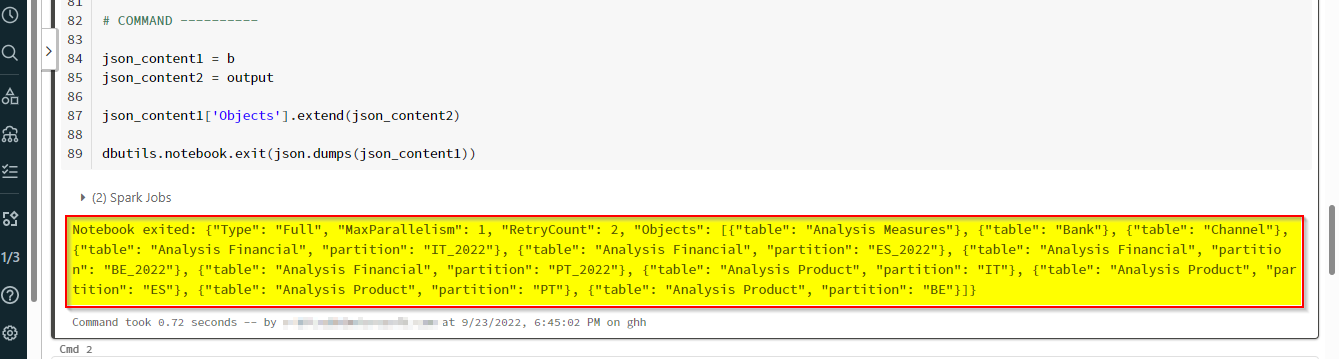
Please check this code for Append two JSON structures and using ['Objects'].extend you will get required output .
json_content1 = b
json_content2 = output
json_content1['Objects'].extend(json_content2)
dbutils.notebook.exit(json.dumps(json_content1))
Output: