I am using spark data bricks cluster in azure, my requirement is to generate json and save json file to databricks storage
But I am getting below error
object of type rdd is not json serializable
code:
df = spark.read.format("csv") \
.option("inferSchema", False) \
.option("header", True) \
.option("sep", ",") \
.load("path-to-file")
df_json = df.toJSON()
file_out="out.json"
with open(file_out, 'w') as f:
json.dump(df_json, f)
How to fix the issue?
CodePudding user response:
The issue arises with json.dump(). For this function to write a JSON file output, a valid JSON object has to be given which is not an RDD (returned by df.toJSON()). I got the same error when I tried using the same code.

- To fix the code, you can get the output of your dataframe as a Dictionary. This can be done using
df_json.collect(). The following will be the output when we usedf_json.collect()for my sample data
print(df_json.collect())

- You can see that above is an array of strings (where each string is json object). You can follow the code below to convert it to a complete JSON dictionary and successfully write it.
output = [eval(i) for i in df_json.collect()]
#output variable has the required generated json
import json
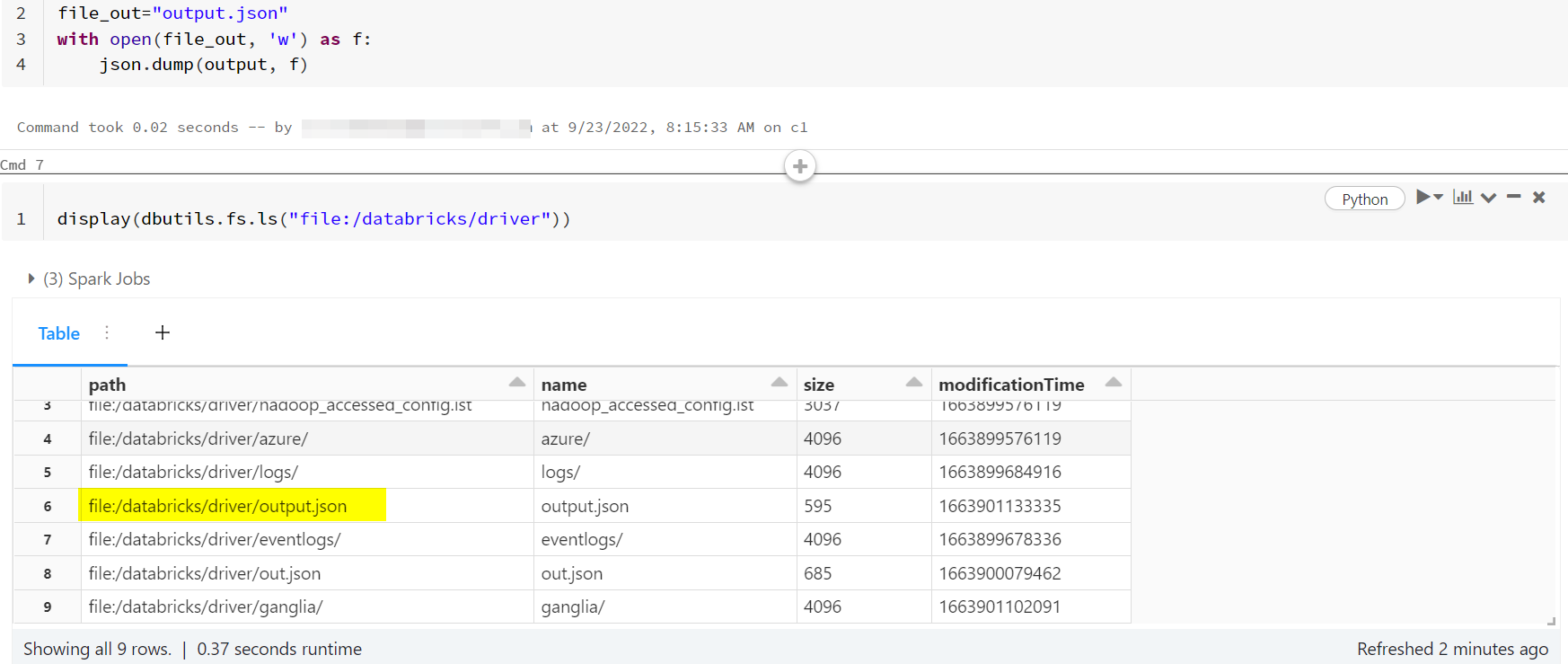
file_out="output.json"
#file would be saved in /databricks/driver/
with open(file_out, 'w') as f:
json.dump(output, f)
- Use
dbutils.fs.ls()to verify./databricks/driver/will be the location of the saved file in Databricks when file path is just filename (file_out="output.json")
display(dbutils.fs.ls("file:/databricks/driver"))
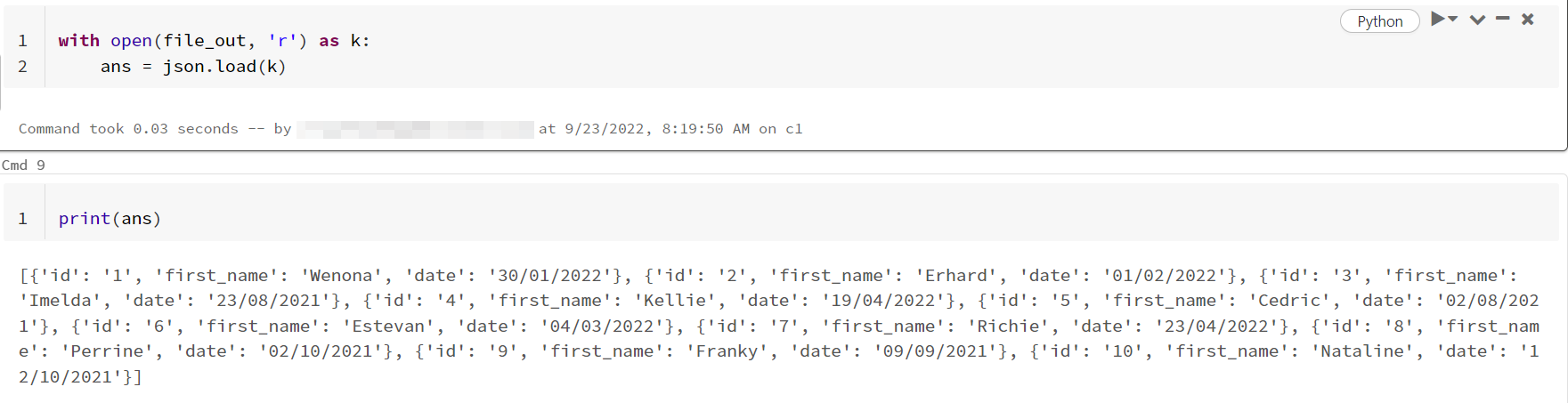
- When I read the same file, you can see that it is successful and given json data.
with open(file_out, 'r') as k:
ans = json.load(k)