I would like to check if items in my lists are in the strings in my column, and know which of them.
Let say I have a PySpark Dataframe containing id and description with 25M rows like this:
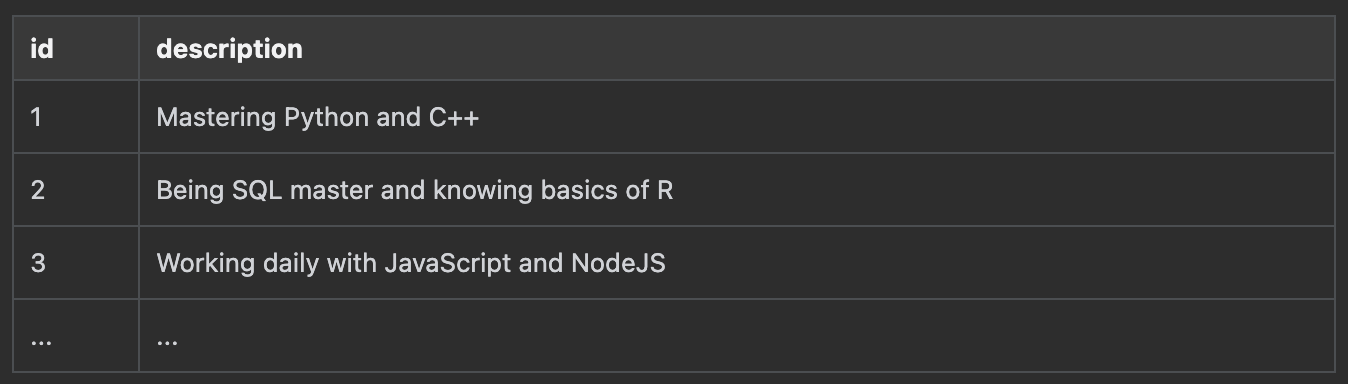
And I have a list of strings like this :
technos = ["SQL", "NodeJS", "R", "C ", "Google Cloud"...]
I would like to check, for each description in my dataframe, which items from the technos list are found.
In output, I would like something like:

Everything I tried until now has failed.
I tried using UDF and a python function with a for loop, but since it doesn’t leverage Spark distributed computing it can't scale with big amount of row.
I recently tried using pyspark.sql.Column.contains followed by pyspark.sql.DataFrame.filter but the filter step is taking so long just for one "techno" and 1M description.
Is there a way to optimize the filter ? I saw something with .join but I don't understand how it can work in my case.
Is it even possible to optimize such a processing with Spark ?
CodePudding user response:
This solution is done in Scala, but the same logic can be applied on Python as well (very simple syntax);
First of all, concatenate your original list: [SQL, NodeJS, R, C\\\\ \\\\ ] to something like this: (SQL)|(NodeJS)|(R)|(C\\\\ \\\\ ).
In Scala, I use: Array.mkString("\"(", ")|(", ")\"") and I store this in a variable, say expr.
Then, assume the dataset is called df and contains:
--- ----------------------------------------
|id |desc |
--- ----------------------------------------
|1 |Being SQL master and knowing basics of R|
|2 |Mastering Python and C |
|3 |Nothing |
--- ----------------------------------------
You can use regexp_extract_all as below:
df.withColumn("technos_found", expr(s"regexp_extract_all(desc, $expr, 0)"))
And gives this:
--- ---------------------------------------- -------------
|id |desc |technos_found|
--- ---------------------------------------- -------------
|1 |Being SQL master and knowing basics of R|[SQL, R] |
|2 |Mastering Python and C |[C ] |
|3 |Nothing |[] |
--- ---------------------------------------- -------------
NOTE: The \\\\ in symbol is very important, as is used for other purposes in regex.
I hope this is what you need, good luck!
CodePudding user response:
from pyspark.sql.types import StringType
from pyspark.sql import functions as F
technos = ["SQL", "NodeJS", "R", "C ", "Python"]
phrases = ['mastering C Python', 'Being SQL master', "working with R"]
df = spark.createDataFrame(technos, StringType())
df1 = spark.createDataFrame(phrases, StringType())
df_exploded = df1.withColumn("items", F.explode(F.split(F.col("value"), ' ')))
df_exploded.show()
-------------------- ---------
| value| items|
-------------------- ---------
|mastering C Python|mastering|
|mastering C Python| C |
|mastering C Python| Python|
| Being SQL master| Being|
| Being SQL master| SQL|
| Being SQL master| master|
| working with R| working|
| working with R| with|
| working with R| R|
-------------------- ---------
df_exploded.join(F.broadcast(df), df.value == df_exploded.items).groupBy(df_exploded.value).agg(F.collect_list(df.value)).show()
-------------------- -------------------
| value|collect_list(value)|
-------------------- -------------------
| working with R| [R]|
|mastering C Python| [C , Python]|
| Being SQL master| [SQL]|
-------------------- -------------------
Here is an example, the key to optimize your performance is to broadcast your technos which I hope won't be very large and you use join to collect all the keys present in your description