I want to parse an xml file in R. It's a Germany parliamentary debate. I managed to get a list of all the <rede> (speech) elements.
Now I want to put the name of the speaker and the speech as a single string into a dataframe. I then want to print the number of speeches, and the content of the first speech.
This is the code I have so far:
session <-read_html("https://www.bundestag.de/resource/blob/909520/ccbb1b470836b419e0e0ab726b679a99/20052-data.xml")
# session Sep 09 2022
# list of all the <rede> elements.
speeches <- session %>%
html_elements("rede") %>%
html_text2()
# name of the speaker, and speech as a single string
bundestag_links <- session %>% html_elements("rede")
bundestag_links
# list of lastnames (nachname) and first names (vorname)
nachname <- bundestag_links %>% html_elements("nachname") %>% html_text2()
nachname
vorname <- bundestag_links %>% html_elements("vorname") %>% html_text2()
vorname
speaker <- do.call(rbind, Map(data.frame, vorname=vorname, nachname=nachname))
unique(speaker$nachname)
unique(speaker$vorname)
speaker <- speaker %>%
distinct()
There are 39 speeches but 51 speakers. Some are dublicates, as some people speak twice so deleting them actually didn't make sense.
I know there is also an ID for the speech and one for the speaker, so I extracted that info too.
# speaker ID
pattern_redner_id <- "redner id=........(\\d)"
redner_id <- bundestag_links %>%
str_extract(pattern_redner_id) %>%
str_remove_all("redner id=")
redner_id
# speech ID
pattern_rede_id <- "ID........(\\d)"
rede_id <- str_extract(bundestag_links, pattern_rede_id)
rede_id
I managed to get one of the speeches into an individual string too.
speakerspeech_1 <- bundestag_links[1] %>% html_elements("p[klasse!=redner]") %>% paste(collapse = " ")
speakerspeech_1
I'm new to parsing and relative new to coding and don't know how to combine this information into one dataframe.
I appreciate any help and recommendations.
CodePudding user response:
Consider using XPath with xml2 package to parse needed content under every <rede> node and bind data together
library(xml2)
url <- paste0(
"https://www.bundestag.de/resource/blob/909520/",
"ccbb1b470836b419e0e0ab726b679a99/20052-data.xml"
)
doc <- read_xml(url)
# RETREIVE ALL rede NODES
redes <- xml_find_all(doc, "//rede")
# BUILD A DATA FRAME OF CONTENT UNDER EACH rede
redes_dfs <- lapply(
redes, function(r)
data.frame(
speech_id = xml_attr(r, "id"),
speaker_id = sapply(xml_find_all(r, "p/redner/@id"), xml_text),
speaker = paste(
sapply(xml_find_all(r, "p/redner/name/vorname"), xml_text),
sapply(xml_find_all(r, "p/redner/name/nachname"), xml_text)
),
speech = paste(
sapply(xml_find_all(r, "p[position() > 1]"), xml_text),
collapse = " "
)
)
)
# BIND ALL DATA FRAMES AND DE-DUPE DATA
speeches_df <- unique(do.call(rbind, redes_dfs))
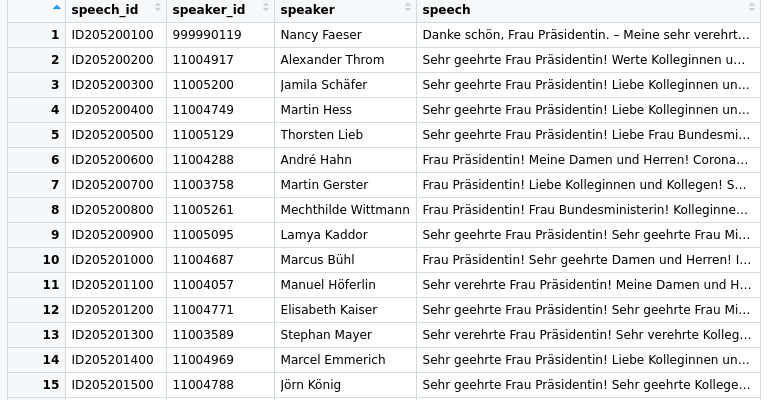
Output
str(speeches_df)
'data.frame': 40 obs. of 4 variables:
$ speech_id : chr "ID205200100" "ID205200200" "ID205200300" "ID205200400" ...
$ speaker_id: chr "999990119" "11004917" "11005200" "11004749" ...
$ speaker : chr "Nancy Faeser" "Alexander Throm" "Jamila Schäfer" "Martin Hess" ...
$ speech : chr "Danke schön, Frau Präsidentin...