I was working on a project where I have to scrape the some text files from a source. I completed this task and I have 140 text file.
 This is one of the text file I have scraped.
This is one of the text file I have scraped.
I am trying to create a dataframe where I should have one row for each text file. So I wrote the below code:-
import pandas as pd
import os
txtfolder = r'/home/spx072/Black_coffer_assignment/' #Change to your folder path
#Find the textfiles
textfiles = []
for root, folder, files in os.walk(txtfolder):
for file in files:
if file.endswith('.txt'):
fullname = os.path.join(root, file)
textfiles.append(fullname)
# textfiles.sort() #Sort the filesnames
#Read each of them to a dataframe
for filenum, file in enumerate(textfiles, 1):
if filenum==1:
df = pd.read_csv(file, names=['data'], sep='delimiter', header=None)
df['Samplename']=os.path.basename(file)
else:
tempdf = pd.read_csv(file, names=['data'], sep='delimiter', header=None)
tempdf['Samplename']=os.path.basename(file)
df = pd.concat([df, tempdf], ignore_index=True)
df = df[['Samplename','data']] #
The code runs fine, but the dataframe I am getting is some thing like this :-
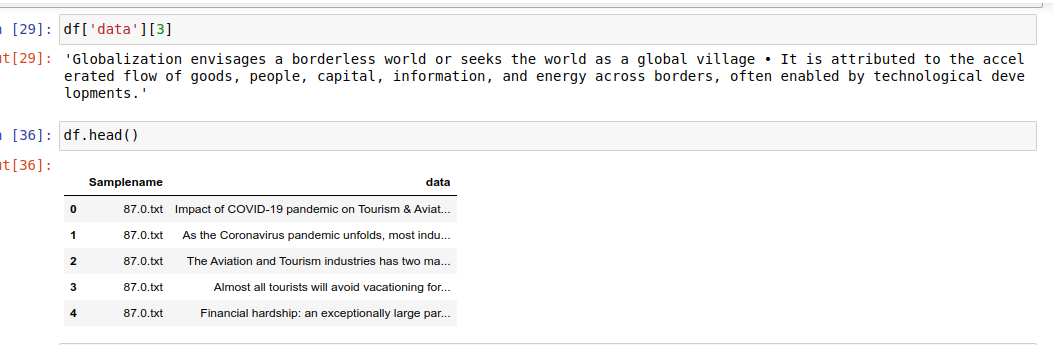
I want that each text file should be inside a single row like:-
1.txt should be in df['data'][0], 2.txt should be in df'data' and so on.
{kind=link}
I tried different codes and also check several questions but still unable to get the desired result. Can anyone help.
CodePudding user response:
I'm not shure why you need pd.read_csv() for this. Try it with pure python:
result = pd.DataFrame(columns=['Samplename', 'data'])
for file in textfiles:
with open(file) as f:
data = f.read()
result = pd.concat([result, pd.DataFrame({'Samplename' : file, 'data': data}, index=[0])], axis=0, ignore_index=True)