I am trying to analyze a large dataset from Yelp. Data is in json file format but it is too large, so script is crahsing when it tries to read all data in same time. So I decided to read line by line and concat the lines in a dataframe to have a proper sample from the data.
f = open('./yelp_academic_dataset_review.json', encoding='utf-8')
I tried without encoding utf-8 but it creates an error. I created a function that reads the file line by line and make a pandas dataframe up to given number of lines. Anyway some lines are lists. And script iterates in each list too and adds to dataframe.
def json_parser(file, max_chunk):
f = open(file)
df = pd.DataFrame([])
for i in range(2, max_chunk 2):
try:
type(f.readlines(i)) == list
for j in range(len(f.readlines(i))):
part = json.loads(f.readlines(i)[j])
df2 = pd.DataFrame(part.items()).T
df2.columns = df2.iloc[0]
df2 = df2.drop(0)
datas = [df2, df]
df2 = pd.concat(datas)
df = df2
except:
f = open(file, encoding = "utf-8")
for j in range(len(f.readlines(i))):
try:
part = json.loads(f.readlines(i)[j-1])
except:
print(i,j)
df2 = pd.DataFrame(part.items()).T
df2.columns = df2.iloc[0]
df2 = df2.drop(0)
datas = [df2, df]
df2 = pd.concat(datas)
df = df2
df2.reset_index(inplace=True, drop=True)
return df2
But still I am having an error that list index out of range. (Yes I used print to debug). So I looked closer to that lines which causes this error.
But very interestingly when I try to look at that lines, script gives me different list.
Here what I meant:
 I runned the cells repeatedly and having different length of the list.
So I looked at lists:
I runned the cells repeatedly and having different length of the list.
So I looked at lists:
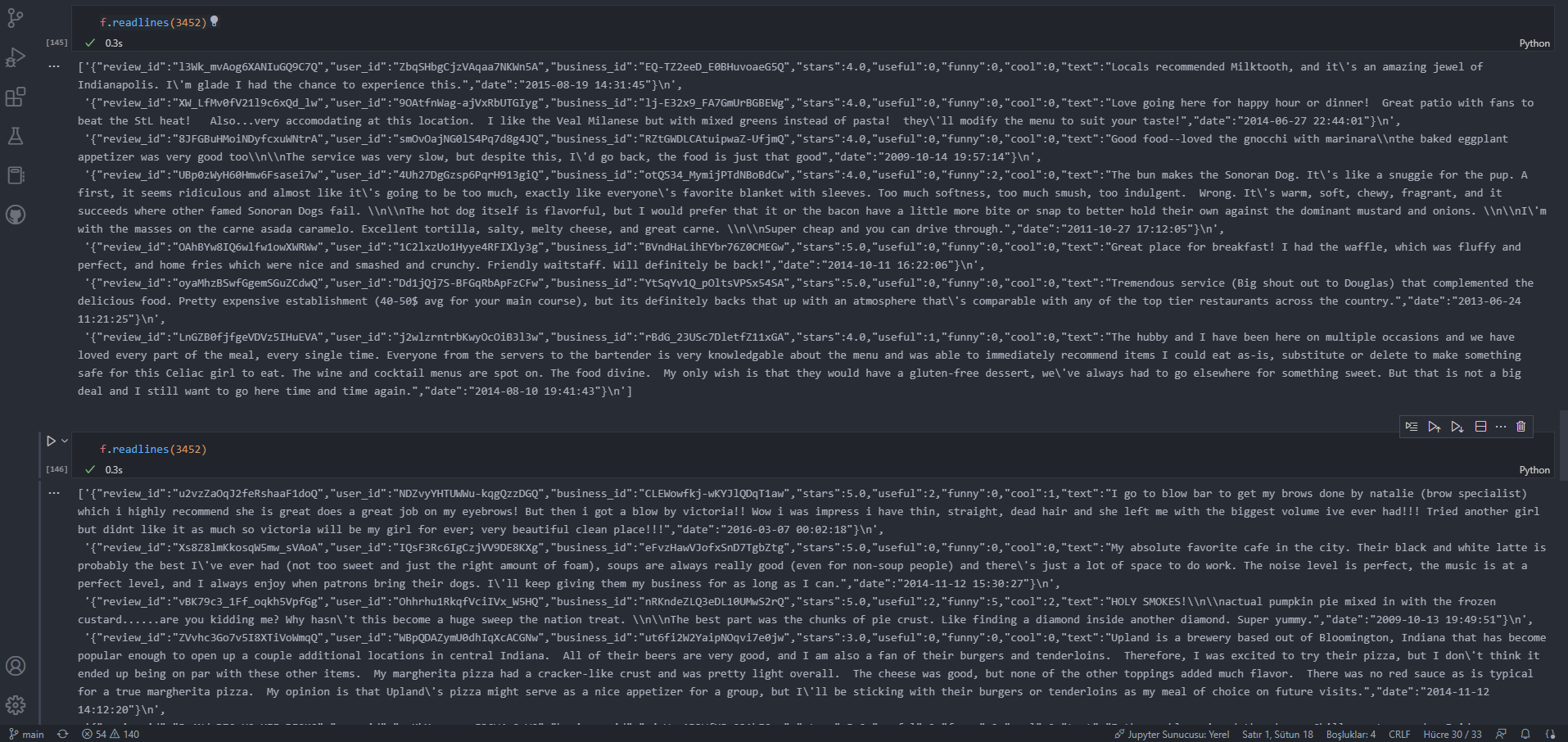
It seems they are completely different lists. In each run it brings different list although line number is same. And readlines documentation is not helping. What am I missing? Thanks in advance.
CodePudding user response:
You are using the expression f.readlines(i) several times as if it was referring to the same set of lines each time.
But as as side effect of evaluating the expression, more lines are actually read from the file. At one point you are basing the indices j on more lines than are actually available, because they came from a different invocation of f.readlines.
You should use f.readlines(i) only once in each iteration of the for i in ... loop and store its result in a variable instead.