I have a PySpark DataFrame and I would like to get the second highest value of ORDERED_TIME (DateTime Field yyyy-mm-dd format) after a groupBy applied to 2 columns, namely CUSTOMER_ID and ADDRESS_ID.
A customer can have many orders associated with an address and I would like to get the second most recent order for a (customer,address) pair
My approach was to make a window and partition according to CUSTOMER_ID and ADDRESS_ID, sort by ORDERED_TIME
sorted_order_times = Window.partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(col('ORDERED_TIME').desc())
df2 = df2.withColumn("second_recent_order", (df2.select("ORDERED_TIME").collect()[1]).over(sorted_order_times))
However, I get an error saying ValueError: 'over' is not in list
Could anyone suggest the right way to go about solving this problem?
Please let me know if any other information is needed
Sample Data
----------- ---------- -------------------
|CUSTOMER_ID|ADDRESS_ID| ORDERED_TIME|
----------- ---------- -------------------
| 100| 158932441|2021-01-02 13:35:57|
| 100| 158932441|2021-01-14 19:14:08|
| 100| 158932441|2021-01-03 13:33:52|
| 100| 158932441|2021-01-04 09:36:10|
| 101| 281838494|2020-05-07 13:35:57|
| 101| 281838494|2021-04-14 19:14:08|
----------- ---------- -------------------
Expected Output
----------- ---------- ------------------- -------------------
|CUSTOMER_ID|ADDRESS_ID| ORDERED_TIME|second_recent_order
----------- ---------- ------------------- -------------------
| 100| 158932441|2021-01-02 13:35:57|2021-01-04 09:36:10
| 100| 158932441|2021-01-14 19:14:08|2021-01-04 09:36:10
| 100| 158932441|2021-01-03 13:33:52|2021-01-04 09:36:10
| 100| 158932441|2021-01-04 09:36:10|2021-01-04 09:36:10
| 101| 281838494|2020-05-07 13:35:57|2020-05-07 13:35:57
| 101| 281838494|2021-04-14 19:14:08|2020-05-07 13:35:57
----------- ---------- ------------------- -------------------
CodePudding user response:
One solution is to create a lookup table with the second most recent orders for all couples of CUSTOMER_ID and ADDRESS_ID, and then join it with the original dataframe.
I assume that your ORDERED_TIME column is already a timestamp type.
import pyspark.sql.functions as F
from pyspark.sql.window import Window
# define window
w = Window().partitionBy('CUSTOMER_ID', 'ADDRESS_ID').orderBy(F.desc('ORDERED_TIME'))
# create lookup table
second_highest = df \
.withColumn('rank', F.dense_rank().over(w)) \
.filter(F.col('rank') == 2) \
.select('CUSTOMER_ID', 'ADDRESS_ID', 'ORDERED_TIME')
# join with original dataframe
df = df.join(second_highest, on=['CUSTOMER_ID', 'ADDRESS_ID'], how='left')
df.show()
----------- ---------- ------------------- -------------------
|CUSTOMER_ID|ADDRESS_ID| ORDERED_TIME| ORDERED_TIME|
----------- ---------- ------------------- -------------------
| 100| 158932441|2021-01-02 13:35:57|2021-01-04 09:36:10|
| 100| 158932441|2021-01-14 19:14:08|2021-01-04 09:36:10|
| 100| 158932441|2021-01-03 13:33:52|2021-01-04 09:36:10|
| 100| 158932441|2021-01-04 09:36:10|2021-01-04 09:36:10|
| 101| 281838494|2020-05-07 13:35:57|2020-05-07 13:35:57|
| 101| 281838494|2021-04-14 19:14:08|2020-05-07 13:35:57|
----------- ---------- ------------------- -------------------
Note: in your expected output you wrote 2021-04-14 19:14:08 for CUSTOMER_ID == 101, but it's actually 2020-05-07 13:35:57 because it's in year 2020.
CodePudding user response:
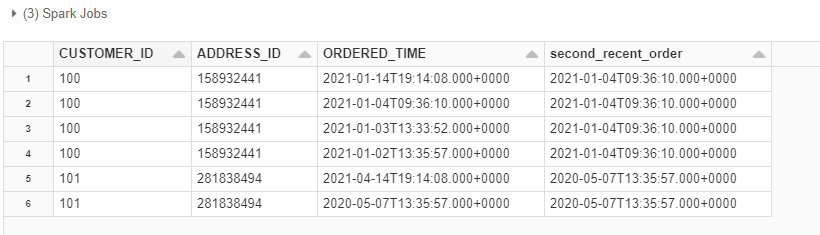
Here is another way to do it. Using collect_list
import pyspark.sql.functions as F
from pyspark.sql import Window
sorted_order_times = Window.partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(F.col('ORDERED_TIME').desc()).rangeBetween(Window.unboundedPreceding, Window.unboundedFollowing)
df2 = (
df
.withColumn("second_recent_order", (F.collect_list(F.col("ORDERED_TIME")).over(sorted_order_times))[1])
)
df2.show()
CodePudding user response:
You can use window here in the following way, but you will get null if only one row would be in a group
sorted_order_times = Window.partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(desc('ORDERED_TIME')).rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)
df2 = df2.withColumn(
"second_recent_order",
collect_list("ORDERED_TIME").over(sorted_order_times).getItem(1)
)