I'm trying to calculate how similar a set is compared to all other sets in a collection by counting the number of elements that match. Once I have the counts, I want to perform further operations against each set with the top X (currently 100) similar sets (ones with the highest count). I have provided an example input and an output which shows the count of matching elements against two sets:
input
{
"list1": [
"label1",
"label2",
"label3"
],
"list2": [
"label2",
"label3",
"label4"
],
"list3": [
"label3",
"label4",
"label5"
],
"list4": [
"label4",
"label5",
"label6"
]
}
output
{
"list1": {
"list1": 3,
"list2": 2,
"list3": 1,
"list4": 0
},
"list2": {
"list1": 2,
"list2": 3,
"list3": 2,
"list4": 1
},
"list3": {
"list1": 1,
"list2": 2,
"list3": 3,
"list4": 2
},
"list4": {
"list1": 0,
"list2": 1,
"list3": 2,
"list4": 3
}
}
I came up with the following code, but it takes hours for an input of about 200,000 sets. The number of elements/labels in a set varies but averages about 10 elements in each set. The total number of unique label values is around 300.
input = {}
input['list1'] = ['label1', 'label2', 'label3']
input['list2'] = ['label2', 'label3', 'label4']
input['list3'] = ['label3', 'label4', 'label5']
input['list4'] = ['label4', 'label5', 'label6']
print(json.dumps(input, indent=2))
input = {key: set(value) for key, value in input.items()}
output = {key1: {key2: 0 for key2 in input.keys()} for key1 in input.keys()}
for key1, value1 in input.items():
for key2, value2 in input.items():
for element in value1:
if element in value2:
count = output[key1][key2]
output[key1][key2] = count 1
print(json.dumps(output, indent=2))
Does anyone have any ideas on how to improve on the execution time of the above code when the number of sets is large?
Thank you for any suggestions!
CodePudding user response:
Use an 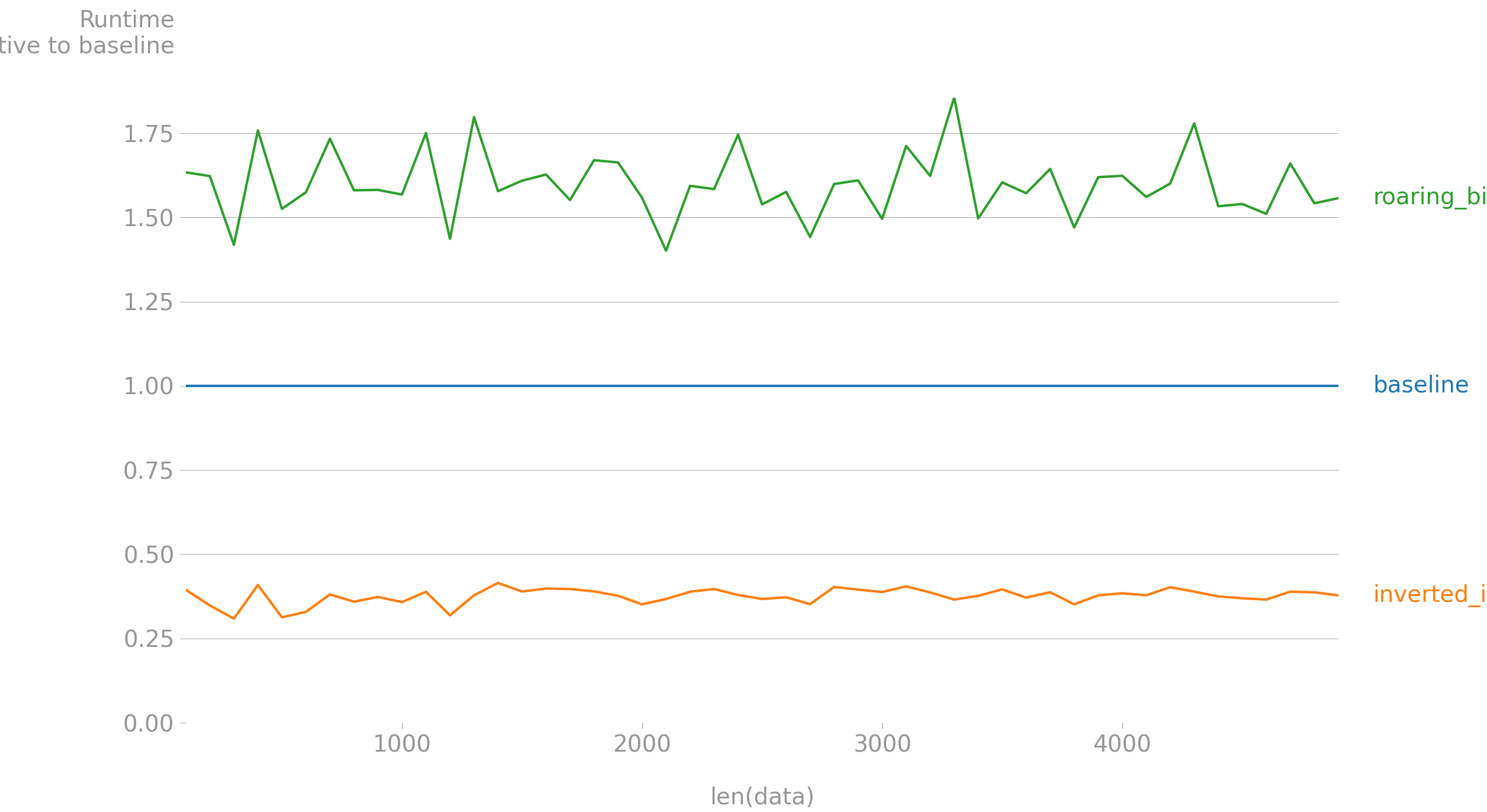
The above graph shows the performance on a dictionary data of length given by the value of the x axis, each value of the dictionary is a list of 10 labels randomly sampled from a population of 100. Against intuition roaring bitmap performs worst than your solution, while using an inverted index takes less than half the time (40 % approximately). The code to reproduce the above results can be found here
CodePudding user response:
Assuming that most pairs of lists have no intersection, the code below should be faster. If it's not fast enough, and approximate results are OK, then you can try min-hashing (set k to lower values for more speed, higher values for more recall).
input = {
"list1": ["label1", "label2", "label3"],
"list2": ["label2", "label3", "label4"],
"list3": ["label3", "label4", "label5"],
"list4": ["label4", "label5", "label6"],
}
import collections
import hashlib
def optional_min_hash(values, k=None):
return (
values
if k is None
else sorted(
hashlib.sha256(str(value).encode("utf8")).digest() for value in values
)[:k]
)
buckets = collections.defaultdict(list)
for key, values in input.items():
for value in optional_min_hash(values):
buckets[value].append(key)
output = collections.defaultdict(dict)
for key1, key2 in {
(key1, key2)
for bucket in buckets.values()
for key1 in bucket
for key2 in bucket
if key1 <= key2
}:
count = len(set(input[key1]) & set(input[key2]))
output[key1][key2] = count
output[key2][key1] = count
print(output)
Sample output:
defaultdict(<class 'dict'>, {'list2': {'list4': 1, 'list1': 2, 'list2': 3, 'list3': 2}, 'list4': {'list2': 1, 'list4': 3, 'list3': 2}, 'list1': {'list2': 2, 'list3': 1, 'list1': 3}, 'list3': {'list1': 1, 'list2': 2, 'list3': 3, 'list4': 2}})