I need the reading of the files to derive to the dataframe, but I didn't find a solution to handle this file format:
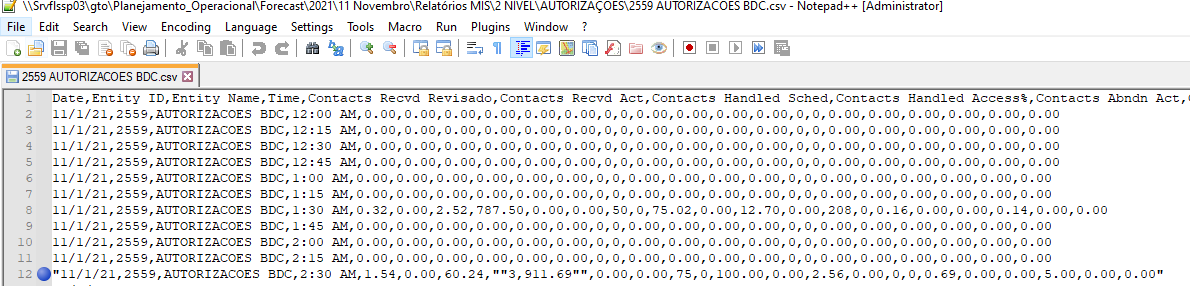
Date,Entity ID,Entity Name,Time,Contacts Recvd Revisado,Contacts Recvd Act,Contacts Handled Sched,Contacts Handled Access%,Contacts Abndn Act,Contacts Abndn Perc,AHT Revisado,AHT Act,Service Level Revisado,Service Level Act,Occupancy Revisado,Occupancy Act,ASA Revisado,ASA Act,Requirements Revisado,Requirements Act,Requirements /-,Sched Open,Staff Est.,Staff - Req
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
this is the code i'm using
import os
import glob
import pandas as pd
path = r'\\Srvflssp03\gto\Planejamento_Operacional\Forecast\2021\11 Novembro\Relatórios MIS'
file_list = glob.glob(os.path.join(path, '**/*.csv'), recursive=True)
combined_csv = pd.concat([pd.read_csv(f,quotechar = '"', sep = ',') for f in file_list ])
DataFrame = pd.DataFrame(combined_csv)
DataFrame.head(11)
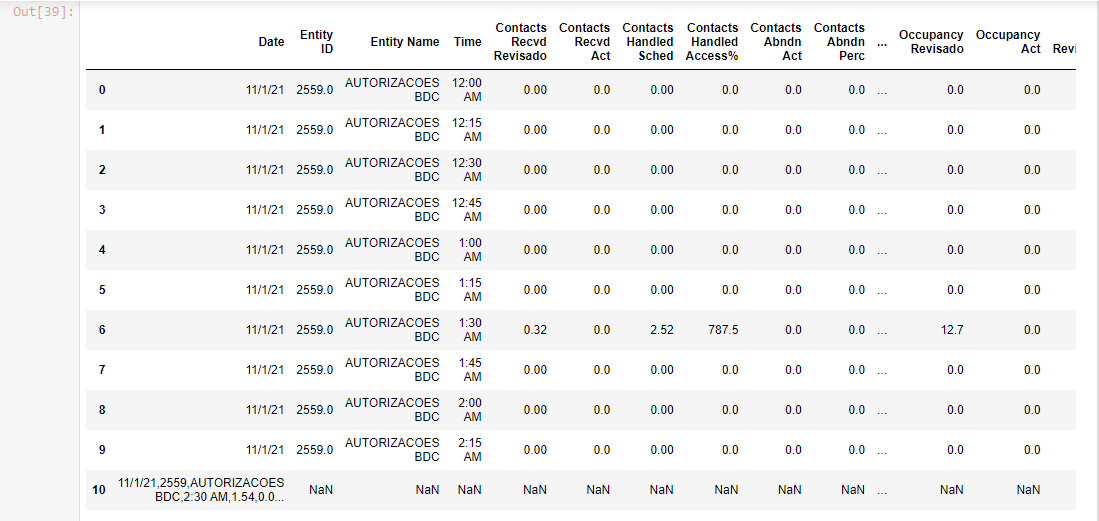
Could anyone tell me what I can do to fix this?
CodePudding user response:
You could read it as normal text, repair line with " ", write all back to file as text, and later read all with pd.read_csv() without problems.
If you already read it then you may try to repair it. You can get text from first column Date and use io.StringIO to read it as csv to another DataFrame - and then you can copy row back to original place.
text = '''Date,Entity ID,Entity Name,Time,Contacts Recvd Revisado,Contacts Recvd Act,Contacts Handled Sched,Contacts Handled Access%,Contacts Abndn Act,Contacts Abndn Perc,AHT Revisado,AHT Act,Service Level Revisado,Service Level Act,Occupancy Revisado,Occupancy Act,ASA Revisado,ASA Act,Requirements Revisado,Requirements Act,Requirements /-,Sched Open,Staff Est.,Staff - Req
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
'''
import pandas as pd
import io
# here I use `io` only to simulate file
df = pd.read_csv(io.StringIO(text))
print(df)
# get string from first column (`Date`) in row `0`
line = df.iloc[0]['Date']
print(line)
# convert to new dataframe
df2 = pd.read_csv(io.StringIO(line), header=None)
print(df2)
# copy back to original dataframe
df.iloc[0] = df2.iloc[0]
print(df)
Result:
# df - before changes
Date ... Staff - Req
0 11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.0... ... NaN
[1 rows x 24 columns]
# string `line`
11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,"3,911.69",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00
# df2
0 1 2 3 4 ... 19 20 21 22 23
0 11/1/21 2559 AUTORIZACOES BDC 2:30 AM 1.54 ... 0.0 0.0 5.0 0.0 0.0
[1 rows x 24 columns]
# df - after changes
Date Entity ID Entity Name ... Sched Open Staff Est. Staff - Req
0 11/1/21 2559.0 AUTORIZACOES BDC ... 5.0 0.0 0.0
[1 rows x 24 columns]
For your full data it will need to use row 10
line = df.iloc[10]['Date']
# ...
df.iloc[10] = df2.iloc[0] # `df2` uses `0`
EDIT:
Version with more rows and with for-loop
text = '''Date,Entity ID,Entity Name,Time,Contacts Recvd Revisado,Contacts Recvd Act,Contacts Handled Sched,Contacts Handled Access%,Contacts Abndn Act,Contacts Abndn Perc,AHT Revisado,AHT Act,Service Level Revisado,Service Level Act,Occupancy Revisado,Occupancy Act,ASA Revisado,ASA Act,Requirements Revisado,Requirements Act,Requirements /-,Sched Open,Staff Est.,Staff - Req
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,"3,911.69",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
'''
import pandas as pd
import io
# here I use `io` only to simulate file
df = pd.read_csv(io.StringIO(text))
print(df)
for index, row in df.iterrows():
# get string from first column (`Date`) in row
line = row['Date']
if ',' in line:
#print(line)
# convert to new dataframe
temp_df = pd.read_csv(io.StringIO(line), header=None)
#print(temp_df)
# copy back to original dataframe
df.iloc[index] = temp_df.iloc[0]
print(df)
and the same with apply() instead of for-loop
text = '''Date,Entity ID,Entity Name,Time,Contacts Recvd Revisado,Contacts Recvd Act,Contacts Handled Sched,Contacts Handled Access%,Contacts Abndn Act,Contacts Abndn Perc,AHT Revisado,AHT Act,Service Level Revisado,Service Level Act,Occupancy Revisado,Occupancy Act,ASA Revisado,ASA Act,Requirements Revisado,Requirements Act,Requirements /-,Sched Open,Staff Est.,Staff - Req
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,"3,911.69",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00
"11/1/21,2559,AUTORIZACOES BDC,2:30 AM,1.54,0.00,60.24,""3,911.69"",0.00,0.00,75,0,100.00,0.00,2.56,0.00,0,0,0.69,0.00,0.00,5.00,0.00,0.00",,,,,,,,,,,,,,,,,,,,,,,
'''
import pandas as pd
import io
# here I use `io` only to simulate file
df = pd.read_csv(io.StringIO(text))
print(df)
def convert(row):
# get string from first column (`Date`) in row
line = row['Date']
if ',' in line:
# convert to new dataframe
temp_df = pd.read_csv(io.StringIO(line), header=None, names=df.columns)
#print(temp_df)
# copy back to original dataframe
row = temp_df.iloc[0]
return row
df = df.apply(convert, axis=1)
print(df)