I thought that I had a very good grasp of pandas data frames, but for some reason, I can convert this dictionary to a dataframe - I'm going to post the full code with constant variables in case someone wants to tag alone:
import pandas as pd
import numpy as np
patches = 26
min_sl = 2.1
max_sl = 104.1
array = np.arange(min_sl, max_sl 1, step=1)
##Creating an array List
array_list = [i for i in array]
## Creating a dictionary
dict_l={i:"" for i in range(1,patches 1)}
## Populating the dictionary
start = 0
end = 4
for i in dict_l:
dict_l[i] = array_list[start:end]
start = start 5
end = end 5
This creates the following dictionary
{1: [2.1, 3.1, 4.1, 5.1],
2: [7.1, 8.1, 9.1, 10.1],
3: [12.1, 13.1, 14.1, 15.1],
4: [17.1, 18.1, 19.1, 20.1],
5: [22.1, 23.1, 24.1, 25.1],
6: [27.1, 28.1, 29.1, 30.1],
7: [32.1, 33.1, 34.1, 35.1],
8: [37.1, 38.1, 39.1, 40.1],
9: [42.1, 43.1, 44.1, 45.1],
10: [47.1, 48.1, 49.1, 50.1],
11: [52.1, 53.1, 54.1, 55.1],
12: [57.1, 58.1, 59.1, 60.1],
13: [62.1, 63.1, 64.1, 65.1],
14: [67.1, 68.1, 69.1, 70.1],
15: [72.1, 73.1, 74.1, 75.1],
16: [77.1, 78.1, 79.1, 80.1],
17: [82.1, 83.1, 84.1, 85.1],
18: [87.1, 88.1, 89.1, 90.1],
19: [92.1, 93.1, 94.1, 95.1],
20: [97.1, 98.1, 99.1, 100.1],
21: [102.1, 103.1, 104.1],
22: [],
23: [],
24: [],
25: [],
26: []}
What I want is a simple dataframe that puts each list in to a row, so for example index 1 will have a list with this values : [2.1, 3.1, 4.1, 5.1],
result = pd.DataFrame.from_dict(dict_l, orient='index')
result
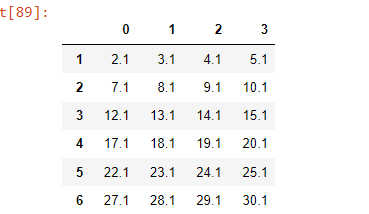
As you can see my result is not what I want, because I want just one column
If I don't specify the function from_dict, I get an error, so I'm wondering if anyone has any idea on how to do this..
I tried to concatenate all columns with a comma, which is in theory what I would like to do:
result['Line Name'] = result[[i for i in range(0,4,1)]].apply(lambda x: ', '.join(x[x.notnull()]), axis=1)
However, I get a type error TypeError: sequence item 0: expected str instance, float found
Does anyone know how to accomplish this?
CodePudding user response:
df = pd.DataFrame({k:[v] for k,v in dict_l.items()}).astype(str)
df = df.stack().reset_index(drop=True)
print(df)
output:
0 [2.1, 3.1, 4.1, 5.1]
1 [7.1, 8.1, 9.1, 10.1]
2 [12.1, 13.1, 14.1, 15.1]
3 [17.1, 18.1, 19.1, 20.1]
4 [22.1, 23.1, 24.1, 25.1]
5 [27.1, 28.1, 29.1, 30.1]
6 [32.1, 33.1, 34.1, 35.1]
7 [37.1, 38.1, 39.1, 40.1]
8 [42.1, 43.1, 44.1, 45.1]
9 [47.1, 48.1, 49.1, 50.1]
10 [52.1, 53.1, 54.1, 55.1]
11 [57.1, 58.1, 59.1, 60.1]
12 [62.1, 63.1, 64.1, 65.1]
13 [67.1, 68.1, 69.1, 70.1]
14 [72.1, 73.1, 74.1, 75.1]
15 [77.1, 78.1, 79.1, 80.1]
16 [82.1, 83.1, 84.1, 85.1]
17 [87.1, 88.1, 89.1, 90.1]
18 [92.1, 93.1, 94.1, 95.1]
19 [97.1, 98.1, 99.1, 100.1]
20 [102.1, 103.1, 104.1]
21 []
22 []
23 []
24 []
25 []
CodePudding user response:
Just put the list in the list:
...
dict_l[i] = [array_list[start:end]]
...
Prints:
0
1 [2.1, 3.1, 4.1, 5.1]
2 [7.1, 8.1, 9.1, 10.1]
3 [12.1, 13.1, 14.1, 15.1]
4 [17.1, 18.1, 19.1, 20.1]
5 [22.1, 23.1, 24.1, 25.1]
6 [27.1, 28.1, 29.1, 30.1]
7 [32.1, 33.1, 34.1, 35.1]
8 [37.1, 38.1, 39.1, 40.1]
9 [42.1, 43.1, 44.1, 45.1]
10 [47.1, 48.1, 49.1, 50.1]
11 [52.1, 53.1, 54.1, 55.1]
12 [57.1, 58.1, 59.1, 60.1]
13 [62.1, 63.1, 64.1, 65.1]
14 [67.1, 68.1, 69.1, 70.1]
15 [72.1, 73.1, 74.1, 75.1]
16 [77.1, 78.1, 79.1, 80.1]
17 [82.1, 83.1, 84.1, 85.1]
18 [87.1, 88.1, 89.1, 90.1]
19 [92.1, 93.1, 94.1, 95.1]
20 [97.1, 98.1, 99.1, 100.1]
21 [102.1, 103.1, 104.1]
22 []
23 []
24 []
25 []
26 []
CodePudding user response:
DataFrames are two-dimensional data structures, so the lists of the dictionary are interpreted as rows. Either construct a Series (1D) and convert it to a DataFrame
result = pd.Series(dict_l).to_frame()
or wrap the dictionary values with extra brackets to create a "3rd dimension".
result = pd.DataFrame([[lst] for lst in dict_l.values()],
index=dict_l.keys())
Output:
>>> result
0
1 [2.1, 3.1, 4.1, 5.1]
2 [7.1, 8.1, 9.1, 10.1]
3 [12.1, 13.1, 14.1, 15.1]
4 [17.1, 18.1, 19.1, 20.1]
5 [22.1, 23.1, 24.1, 25.1]
6 [27.1, 28.1, 29.1, 30.1]
7 [32.1, 33.1, 34.1, 35.1]
8 [37.1, 38.1, 39.1, 40.1]
9 [42.1, 43.1, 44.1, 45.1]
10 [47.1, 48.1, 49.1, 50.1]
11 [52.1, 53.1, 54.1, 55.1]
12 [57.1, 58.1, 59.1, 60.1]
13 [62.1, 63.1, 64.1, 65.1]
14 [67.1, 68.1, 69.1, 70.1]
15 [72.1, 73.1, 74.1, 75.1]
16 [77.1, 78.1, 79.1, 80.1]
17 [82.1, 83.1, 84.1, 85.1]
18 [87.1, 88.1, 89.1, 90.1]
19 [92.1, 93.1, 94.1, 95.1]
20 [97.1, 98.1, 99.1, 100.1]
21 [102.1, 103.1, 104.1]
22 []
23 []
24 []
25 []
26 []