Hello everyone I am learning python I am new I have a column in a csv file with this example of value:
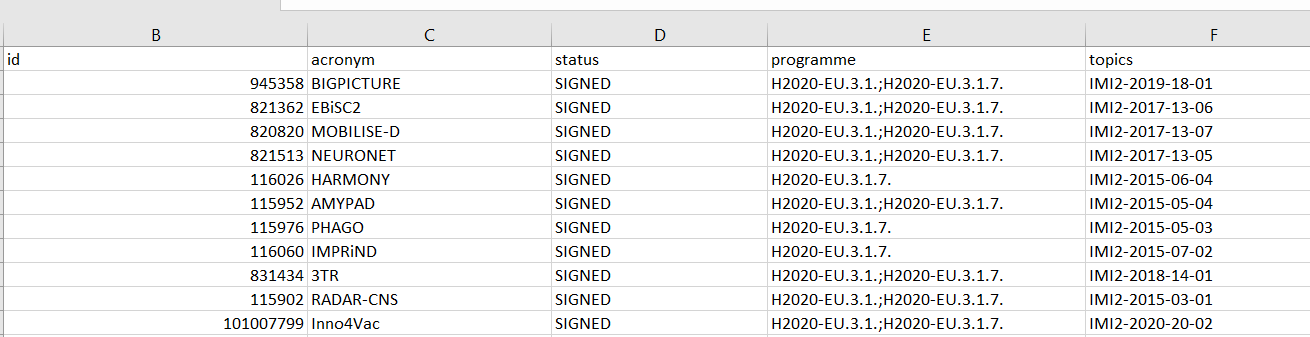
I want to divide the column programme based on that semi column into two columns for example
program 1: H2020-EU.3.1.
program 2: H2020-EU.3.1.7.
This is what I wrote initially
import csv
import os
with open('IMI.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
with open('new_IMI.csv', 'w') as new_file:
csv_writer = csv.writer(new_file, delimiter='\t')
#for line in csv_reader:
# csv_writer.writerow(line)
please note that after i do the split of columns I need to write the file again as a csv and save it to my computer
Please guide me
CodePudding user response:
Using .loc to iterate through each row of a dataframe is somewhat inefficient. Better to split an entire column, with the expand=True to assign to the new columns. Also as stated, easy to use pandas here:
Code:
import pandas as pd
df = pd.read_csv('IMI.csv')
df[['programme1','programme2']] = df['programme'].str.split(';', expand=True)
df.drop(['programme'], axis=1, inplace=True)
df.to_csv('IMI.csv', index=False)
Example of output:
Before:
print(df)
id acronym status programme topics
0 945358 BIGPICTURE SIGNED H2020-EU.3.1.;H2020-EU3.1.7 IMI2-2019-18-01
1 821362 EBiSC2 SIGNED H2020-EU.3.1.;H2020-EU3.1.7 IMI2-2017-13-06
2 116026 HARMONY SIGNED H202-EU.3.1. IMI2-2015-06-04
After:
print(df)
id acronym status topics programme1 programme2
0 945358 BIGPICTURE SIGNED IMI2-2019-18-01 H2020-EU.3.1. H2020-EU3.1.7
1 821362 EBiSC2 SIGNED IMI2-2017-13-06 H2020-EU.3.1. H2020-EU3.1.7
2 116026 HARMONY SIGNED IMI2-2015-06-04 H2020-EU.3.1. None
CodePudding user response:
You can use pandas library instead of csv.
import pandas as pd
df = pd.read_csv('IMI.csv')
p1 = {}
p2 = {}
for i in range(len(df)):
if ';' in df['programme'].loc[i]:
p1[df['id'].loc[i]] = df['programme'].loc[i].split(';')[0]
p2[df['id'].loc[i]] = df['programme'].loc[i].split(';')[1]
df['programme1'] = df['id'].map(p1)
df['programme2'] = df['id'].map(p2)
and if you want to delete programme column:
df.drop('programme', axis=1)
To save new csv file:
df.to_csv('new_file.csv', inplace=True)