I have a Dataframe with several lines and columns and I have transformed it into a numpy array to speed-up the calculations. The first five columns of the Dataframe looked like this:
par1 par2 par3 par4 par5
1.502366 2.425301 0.990374 1.404174 1.929536
1.330468 1.460574 0.917349 1.172675 0.766603
1.212440 1.457865 0.947623 1.235930 0.890041
1.222362 1.348485 0.963692 1.241781 0.892205
...
These columns are now stored in a numpy array a = df.values
I need to check whether at least two of the five columns satisfy a condition (i.e., their value is larger than a certain threshold). Initially I wrote a function that performed the operation directly on the dataframe. However, because I have a very large amount of data and need to repeat the calculations over and over, I switched to numpy to take advantage of the vectorization.
To check the condition I was thinking to use
df['Result'] = np.where(condition_on_parameters > 2, True, False)
However, I cannot figure out how to write the condition_on_parameters such that it returns a True of False when at least 2 out of the 5 parameters are larger than the threshold. I thought to use the sum() function on the condition_on_parameters but I am not sure how to write such condition.
EDIT
It is important to specify that the thresholds are different for each parameter. For example thr1=1.2, thr2=2.0, thr3=1.5, thr4=2.2, thr5=3.0. So I need to check that par1 > thr1, par2 > thr2, ..., par5 > thr5.
CodePudding user response:
Assuming condition_on_parameters returns an array the sames size as a with entries as True or False, you can use np.sum(condition_on_parameters, axis=1) to sum over the true values (True has a numerical values of 1) of each row. This provides a 1D array with entries as the number of columns that meet the condition. This array can then be used with where to get the row numbers you are looking for.
df['result'] = np.where(np.sum(condition_on_parameters, axis=1) > 2)
CodePudding user response:
It seems you are looking for 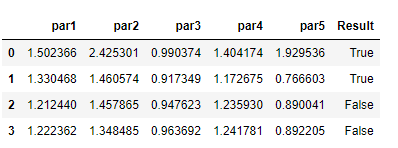
CodePudding user response:
Can you exploit pandas functionalities? For example, you can efficiently check conditions on multiple rows/columns with .apply and then .sum(axis=1).
Here some sample code:
import pandas as pd
df = pd.DataFrame([[1.50, 2.42, 0.88], [0.98,1.3, 0.56]], columns=['par1', 'par2', 'par3'])
# custom_condition, e.g. value less or equal than threshold
def leq(x, t):
return x<=t
condition = df.apply(lambda x: leq(x, 1)).sum(axis=1)
# filter
df.loc[condition >=2]
I think this should be equivalent to numpy in terms of efficiency as pandas is ultimately build on top of that, however I'm not entirely sure...