I have two features datetime and volt for 1000 machineIDs. I am printing datetime and volt using matplotlib. Now, some machineIDs have unique values like there are 6-7 unique lines and hence there are multiple lines on the graph. Like this,
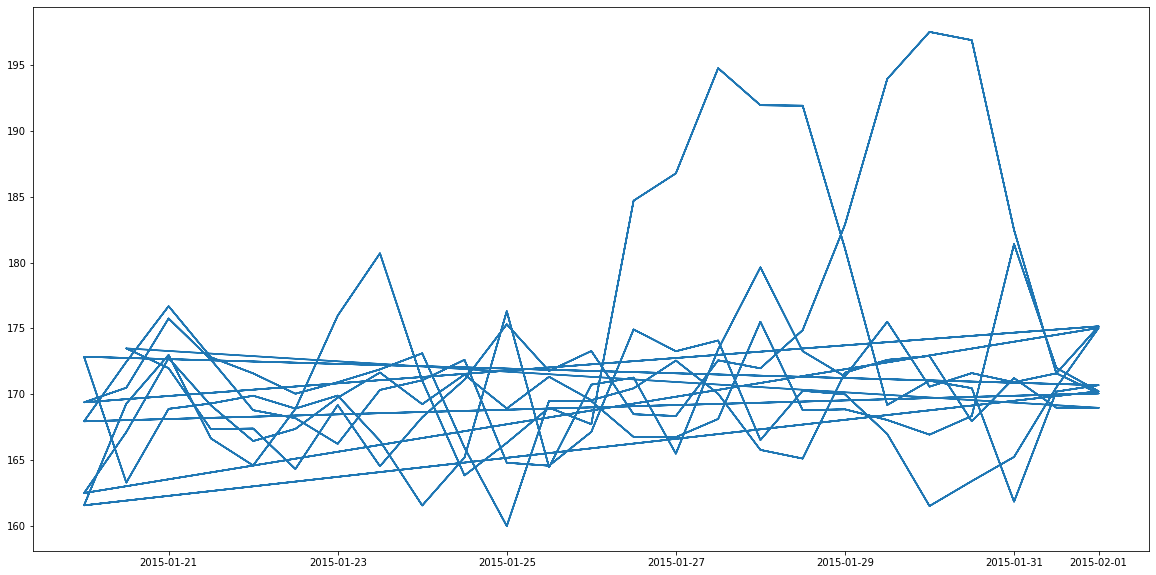
I want to segregate these lines in different colors for different machineIDs. Problem is I am plotting for datetime and volt only . So how do I do this?
Here is a sample data
machineID dt_truncated volt_rollingmean_12 label_e
964 2015-01-27 12:00:00 194.788225 1
Here I am plotting b/w volt and dt_truncated based on value of label_e. If label_e is1, then we consider it for plot. But there are 1000 machine IDs and because of that there are 6-7 different lines on plot.
As per the answer by quest I am getting this plot
CodePudding user response:
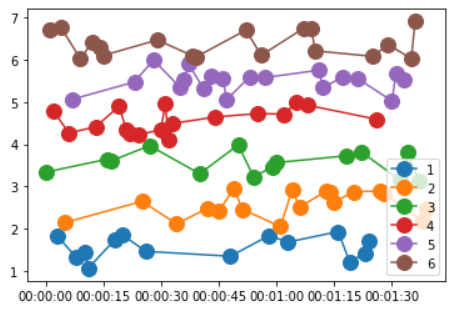
Here is how you can go about it:
fig, ax = plt.subplots()
groups = df.groupby('machineID')
for name, group in groups:
group = group.sort_values("dt_truncated")
ax.plot(group.dt_truncated, group.volt_rollingmean_12, marker='o', ms=12, label=group.machineID.unique()[0])
ax.legend()
Here is the output:
CodePudding user response:
Pivot your dataframe before plot:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dti = pd.date_range('2021-12-20', '2021-12-26')
df = pd.DataFrame({'machineID': np.repeat(range(1, 6), len(dti)),
'dt_truncated': dti.tolist()*5,
'volt_rollingmean_12': np.random.randint(160, 380, 5*len(dti))})
df.pivot('dt_truncated', 'machineID', 'volt_rollingmean_12').plot()
plt.show()
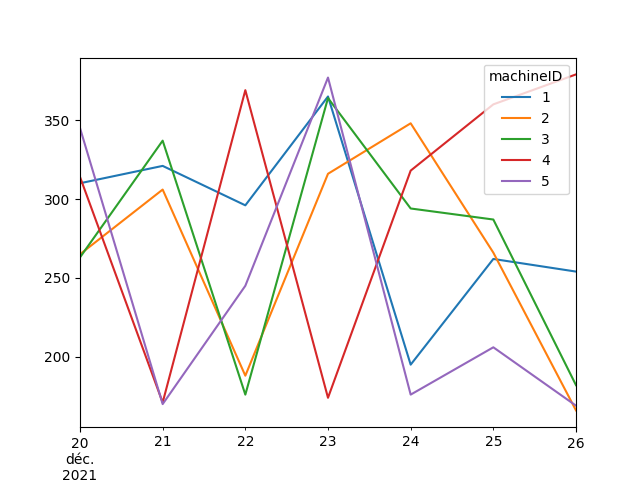
To filter on label_e:
df[df['label_e'] == 1].pivot(...).plot()