I'm tying to get dimensions from a website. The table present on the page is in this format and details as color, dimensions, material and so on, are not all the time in the same order[as it can be noticed in the image examples below].
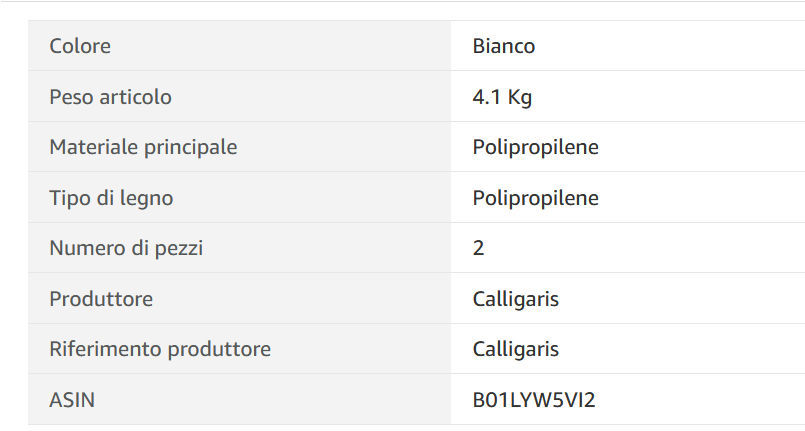

I am interested to extract this 'Peso articolo' value which can be also found as 'Peso do produto' or 'Peso del producto'. The issue is that Xpath for this is different from a page to another and the class is the same for all the details from the table.
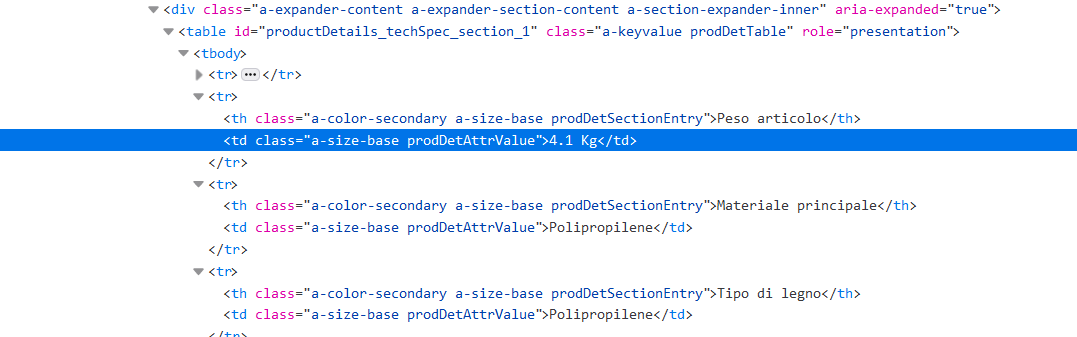
I'm using this code to extract but since the position is different on each page, sometimes extracts material for example instead of dimension[using Xpath].
def get_dimensions(driver):
# details XPATH
# details_xpath = '//*[@id="productDetails_techSpec_section_1"]/tbody/tr[4]/td'
details_xpath = '/html/body/div[2]/div[2]/div[3]/div[8]/div[7]/div/div/div/div[1]/div[1]/div/div[2]/div/div/table/tbody/tr[2]/td'
found = False
retries = 1
dimensions = ''
while retries > 0 and not found:
try:
retries = retries - 1
dimensions_elem = WebDriverWait(driver, 1).until(
EC.presence_of_element_located((By.XPATH, details_xpath))
)
found = True
dimensions = dimensions_elem.text
except:
pass
print('dimensions not found! Retrying...')
return dimensions
Is there a way I could update this to access only those th classes where the value is 'Peso articolo' or 'Peso do produto' or 'Peso del producto' and get the value from the td class?

CodePudding user response:
To get td tag wrt to th tag value Peso articolo Use any of the following xpath to get the element.
details_xpath ="//th[normalize-space(text())='Peso articolo']/following::td[1]"
or
details_xpath ="//tr[./th[normalize-space(text())='Peso articolo']]/td"