I am a Pandas newbie and I am trying to automate the processing of ticket data we get from our IT ticketing system. After experimenting I was able to get 80 percent of the way to the result I am looking for.
Currently I pull in the ticket data from a CSV into a "df" dataframe. I then want to summarize the data for the higher ups to review and get high level info like totals and average "age" of tickets (number of days between ticket creation date and current date).
Here's an example of the ticket data for "df" dataframe:
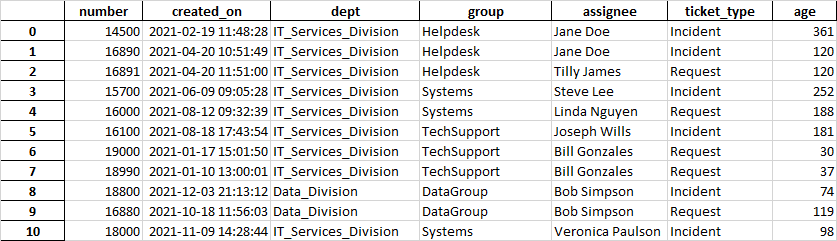
I then create "df2" dataframe to summarize df using:
df2 = df.groupby(["dept", "group", "assignee", "ticket_type"]).agg(task_count=('ticket_type', 'size'), mean_age_in_days=('age', 'mean'),)
And here's what it I am getting if I print out df2...which is very close to what I need.
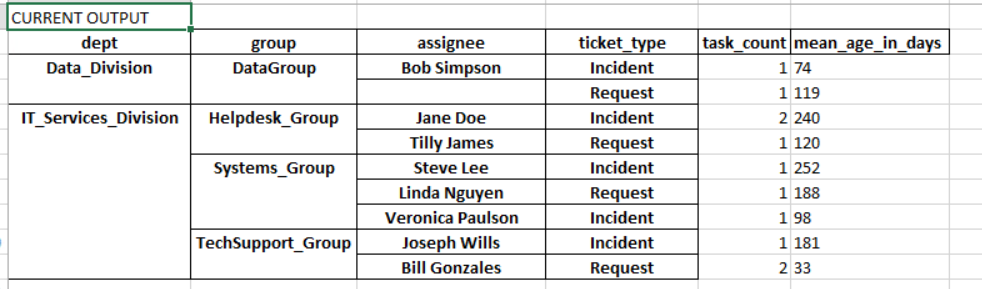
As you can see we look at the count of tickets assigned to each staff member, separated by type (incident, request), and also look at the average "age" of each ticket type (incident, request) for each staff member.
The roadblock that I am hitting now and have been pulling my hair out about is I need to show the aggregates (count and averages of ages) at all 3 levels (sorry if I am using the wrong jargon). Basically I need to show the count and average age for all tickets associated with a group, then the same thing for tickets at the department ("Division") level, and lastly the grand total and grand average in green...for all tickets which is the entire organization (all tickets in all departments, groups).
Here's an example of the ideal result I am trying to get:
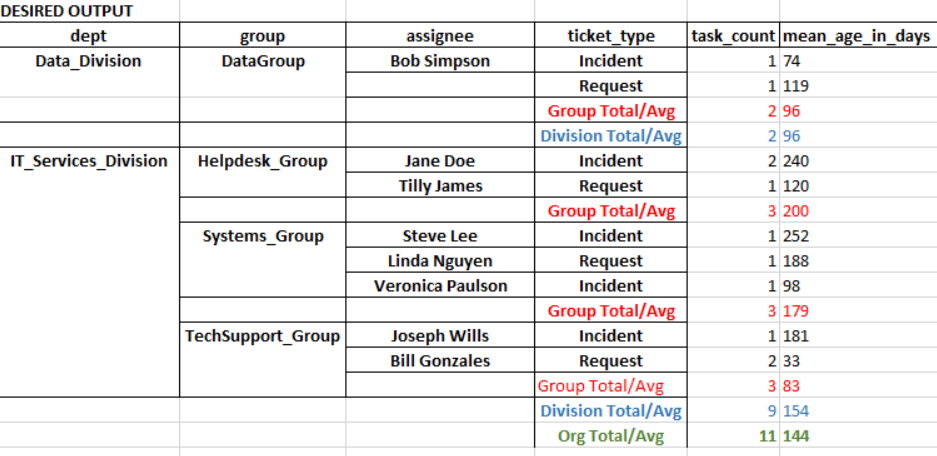
You will see in red I want the count of tickets and average age for tickets for a given group. Then, in blue I want the count and average age for all tickets on the dept/division level (all tickets for all groups belonging to a given dept./division). Lastly, I want the grand total and grand average for all tickets in the entire organization. In the end both the df2 (summary of ticket data) and df will be dumped to an Excel file on separate worksheets in the same workbook.
Please have mercy on me! Can someone show me how I could generate the desired "summary" with counts and average age at all levels (group, dept., and organization)? Thanks in advance for any assistance, I'd really, really appreciate it!
*Added link to CSV with sample ticket data below:
CodePudding user response:
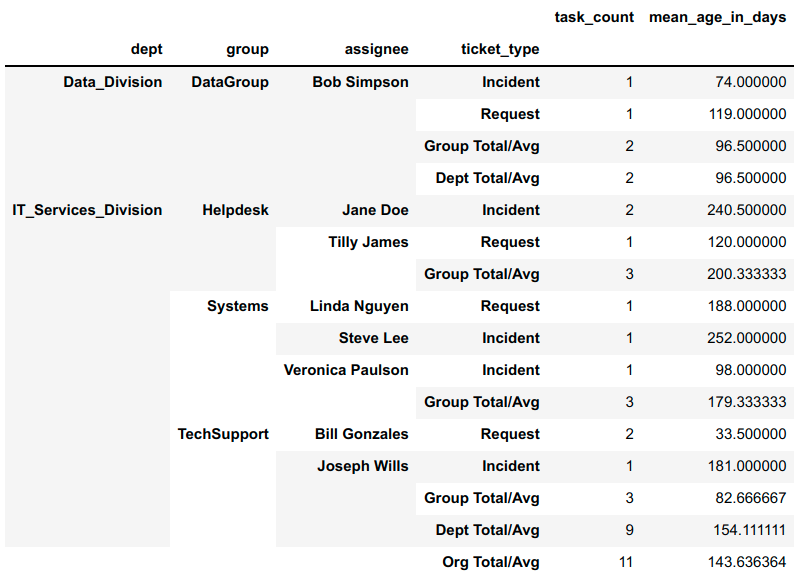
Here's a different approach which is easier, but results in a different structure
agg_df = df.copy()
#Add dept-level info to the department
gb = agg_df.groupby('dept')
task_counts = gb['ticket_type'].transform('count').astype(str)
mean_ages = gb['age'].transform('mean').round(2).astype(str)
agg_df['dept'] = ' [' task_counts ' tasks, avg age= ' mean_ages ']'
#Add group-level info to the group label
gb = agg_df.groupby(['dept','group'])
task_counts = gb['ticket_type'].transform('count').astype(str)
mean_ages = gb['age'].transform('mean').round(2).astype(str)
agg_df['group'] = ' [' task_counts ' tasks, avg age= ' mean_ages ']'
#Add org-level info
agg_df['org'] = 'Org [{} tasks, avg age = {}]'.format(len(agg_df),agg_df['age'].mean().round(2))
agg_df = (
agg_df.groupby(['org','dept','group','assignee','ticket_type']).agg(
task_count=('ticket_type','count'),
mean_ticket_age=('age','mean'))
)
agg_df
