The reason I'm using Chrome-Headless is because it's acts like a real browser, but when I direct chrome-headless Selenium to this Barnes and Noble link:
I get this response, without navigating to any other page
<html><head>
<title>Access Denied</title>
</head><body>
<h1>Access Denied</h1>
You don't have permission to access "https://www.barnesandnoble.com/w/the-woman-they-could-not-silence-kate-moore/1138489968?ean=9781728242576" on this server.<p>
Reference #
</p></body></html>
I understand that I would need to add headers and all, but how is this different than just a regular GET request Headers?
What else is giving Chrome-headless away to the Barnes and Nobel in particular?
What am I doing wrong?
What am I missing?
CodePudding user response:
You are seeing the following Access Denied error page:
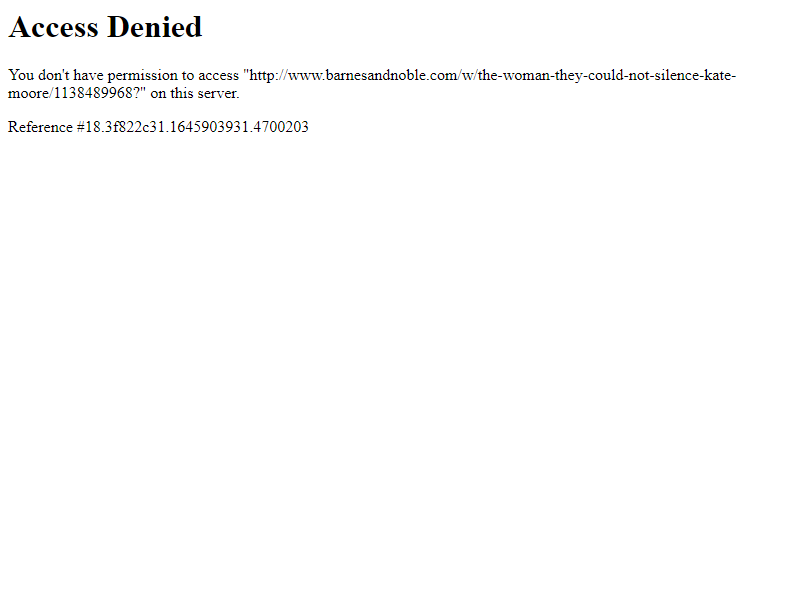
due to presence of the keyword Headless within the user-agent
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/98.0.4758.102 Safari/537.36
Solution
You can override the default useragent with some other regular UserAgent as follows:
Code Block:
options = Options() options.headless = True options.add_argument("start-maximized") options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) options.add_argument('--disable-blink-features=AutomationControlled') options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36") s = Service('C:\\BrowserDrivers\\chromedriver.exe') driver = webdriver.Chrome(service=s, options=options) driver.get("https://www.barnesandnoble.com/w/the-woman-they-could-not-silence-kate-moore/1138489968?ean=9781728242576") driver.save_screenshot("barnesandnoble.png")Screenshot:
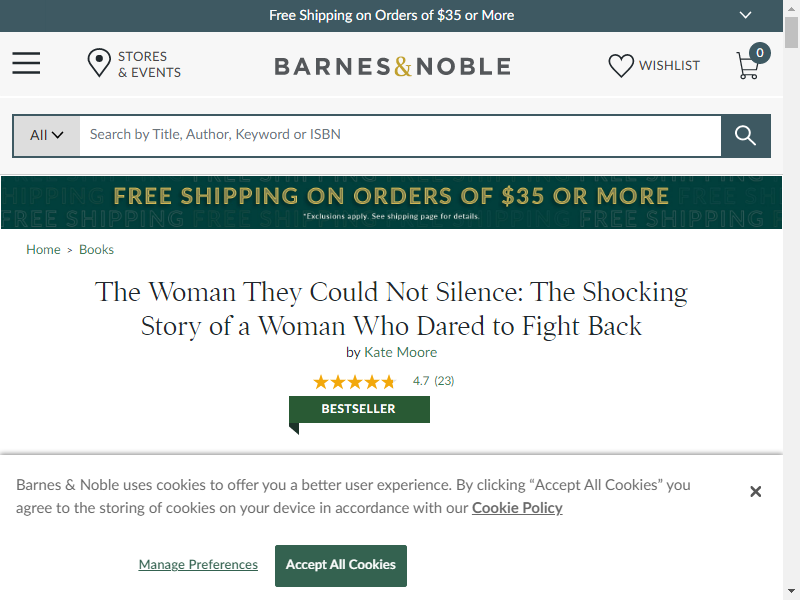
References
You can find a couple of relevant detailed discussions in: