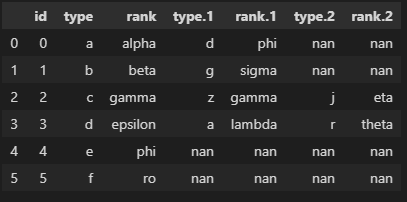
I have a little problem with the transformation from wide to long on a dataset. I tried with melt but I didn't get a good result. I hope that someone could help me. The dataset is as follow:
pd.DataFrame({'id': [0, 1, 2, 3, 4, 5],
'type': ['a', 'b', 'c', 'd', 'e', 'f'],
'rank': ['alpha', 'beta', 'gamma', 'epsilon', 'phi', 'ro'],
'type.1': ['d', 'g', 'z', 'a', 'nan', 'nan'],
'rank.1': ['phi', 'sigma', 'gamma', 'lambda', 'nan', 'nan'],
'type.2': ['nan', 'nan', 'j', 'r', 'nan', 'nan'],
'rank.2': ['nan', 'nan', 'eta', 'theta', 'nan', 'nan']})
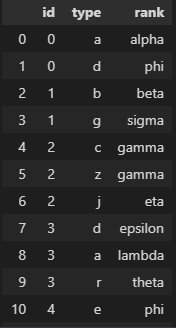
And I need the dataset in this way:
pd.DataFrame({'id': [0, 0, 1, 1, 2, 2, 2, 3, 3, 3, 4, 5],
'type': ['a', 'd', 'b', 'g', 'c', 'z', 'j', 'd', 'a', 'r', 'e', 'f'],
'rank': ['alpha', 'phi', 'beta', 'sigma', 'gamma', 'gamma', 'eta', 'epsilon', 'lambda', 'theta', 'phi', 'ro']})
Can anyone help me with that? Thanks a lot
CodePudding user response:
Use wide_to_long:
# normalize the `type` and `rank` columns so they have the same format as others
df = df.rename(columns={'type': 'type.0', 'rank': 'rank.0'})
(pd.wide_to_long(df, stubnames=['type', 'rank'], i='id', j='var', sep='.')
[lambda x: (x['type'] != 'nan') | (x['rank'] != 'nan')].reset_index())
id var type rank
0 0 0 a alpha
1 1 0 b beta
2 2 0 c gamma
3 3 0 d epsilon
4 4 0 e phi
5 5 0 f ro
6 0 1 d phi
7 1 1 g sigma
8 2 1 z gamma
9 3 1 a lambda
10 2 2 j eta
11 3 2 r theta
You can drop the var column if not needed.