I have the following database. My intention is to subtract the scores of each name according to the category and Index. That is b - a of every name according the index.
My database
dat <- read.table(text="
Name Score Index Category
Pepe 5 Al a
Pepe 1 Bl b
Juan 8 Cl a
Juan 5 Al b
Mikel 1 Cl a
Mikel 6 Bl b
", header=TRUE)
I want obtain this:
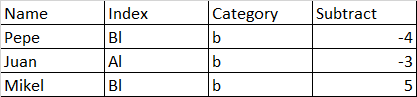
Can you help me, please?
CodePudding user response:
Here are two ways, base R and package dplyr.
Base R
Use aggregate to compute the differences, then merge with the original data set to have the other columns in the result and subset by Category.
To keep the names order, the 2nd solution uses order to first get an index i.
df1 <- data.frame(
Name = c("Pepe", "Pepe", "Juan", "Juan", "Mikel", "Mikel"),
Score = c(5,1,8,5,1,6),
Index = rep(c("AI", "BI", "CI"), 2),
Category = rep(c("a", "b"), 3)
)
merge(
aggregate(Score ~ Name, df1, diff),
subset(df1, select = -Score),
by = "Name"
) |> subset(Category == "b")
#> Name Score Index Category
#> 2 Juan -3 AI b
#> 4 Mikel 5 CI b
#> 6 Pepe -4 BI b
i <- order(unique(df1$Name))
merge(
aggregate(Score ~ Name, df1, diff),
subset(df1, select = -Score),
by = "Name"
) |> subset(Category == "b") |>
(\(x) x[order(i), ])()
#> Name Score Index Category
#> 6 Pepe -4 BI b
#> 2 Juan -3 AI b
#> 4 Mikel 5 CI b
Created on 2022-03-10 by the reprex package (v2.0.1)
Package dplyr
The same algorithm as above but with dplyr functions.
suppressPackageStartupMessages(library(dplyr))
left_join(
df1 %>% group_by(Name) %>% summarise(Score = diff(Score)),
df1 %>% select(-Score),
by = "Name"
) %>%
filter(Category == "b")
#> # A tibble: 3 x 4
#> Name Score Index Category
#> <chr> <dbl> <chr> <chr>
#> 1 Juan -3 AI b
#> 2 Mikel 5 CI b
#> 3 Pepe -4 BI b
Created on 2022-03-10 by the reprex package (v2.0.1)