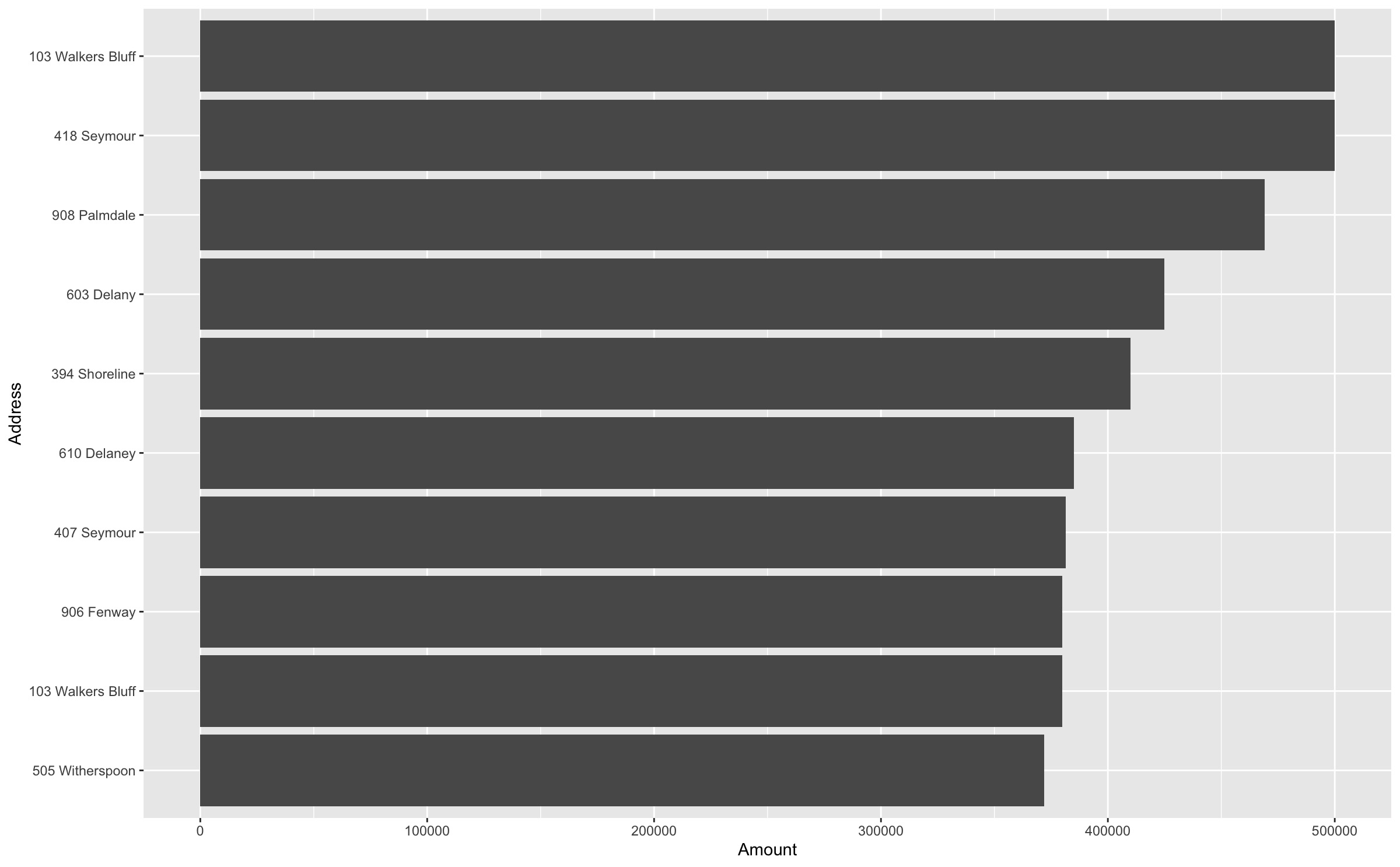
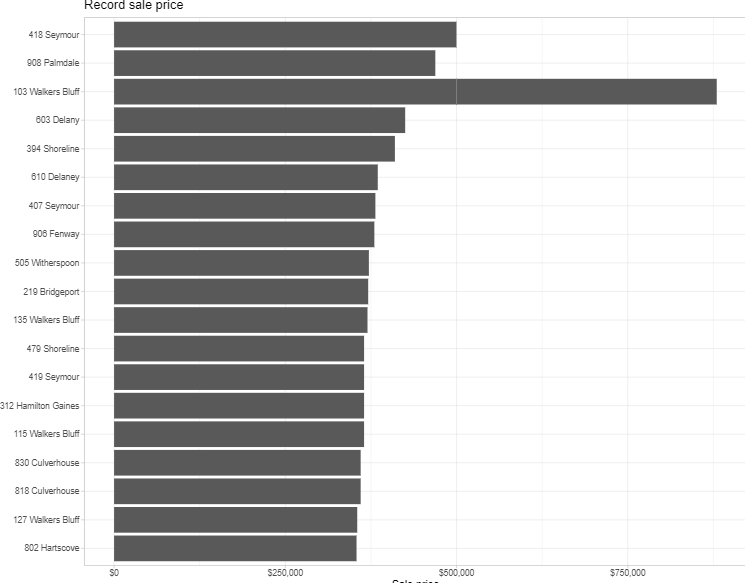
I'm tracking home sales in my immediate neighborhood and would like to track things like maximum and minimum times on market and sales price.
Some homes have been sold at least twice in the last few year and the column plot stacks both values, e.g.
homesales %>%
slice_max(amount, n = 20) %>%
ggplot(aes(y = fct_reorder(address, amount), x = amount))
geom_col()
The home that has been sold twice (and shows up twice in the slice_max because of high sales price) is plotted as a stacked column instead of two separate columns at two places in the ranking.
Is there a way to decouple the values in the geom_col plot?
For clarity: I'm aware of the position = "dodge" option. Because the sales prices show up in different positions in the ranking, this is not what I'm looking for. Each sale should be in its appropriate rank location.
--edit-- example
address,amount,saledate
103 Walkers Bluff,500000,2022-04-14
418 Seymour,499900,2022-03-15
908 Palmdale,469000,2021-10-06
603 Delany,425000,2021-05-26
394 Shoreline,410000,2021-09-24
610 Delaney,385000,2021-03-03
407 Seymour,381500,2021-06-30
906 Fenway,380000,2019-02-27
103 Walkers Bluff,379900,2019-08-12
505 Witherspoon,372000,2021-03-31
CodePudding user response:
We can use interaction to create a unique variable (as @DanAdams recommended), then we can adjust the labels so that it only shows the address with scale_y_discrete.
library(tidyverse)
homesales %>%
slice_max(amount, n = 20) %>%
ggplot(aes(y = fct_reorder(interaction(address, saledate), amount), x = amount))
scale_y_discrete(labels = homesales %>% arrange(amount) %>% pull(address))
geom_col()
xlab("Amount")
ylab("Address")
Output