df =pd.DataFrame(eval(res))
print(df.head())
df.to_csv('data.csv',index=False)
This is my code to convert the data i need to a csv file but because the data is a dictionary, of a list of rougly 70 other dictionaries i can't get the format the way i want.
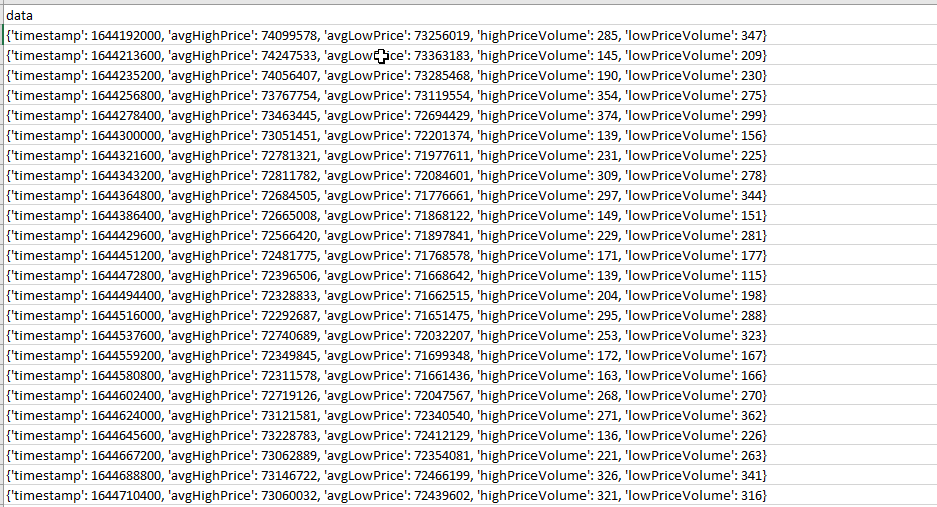 here i want timestamp to be my first column and then each key after that to be another column with the prices/volume at each unix timestep. How can i modify my code to achieve this? I dont need the data column.
here i want timestamp to be my first column and then each key after that to be another column with the prices/volume at each unix timestep. How can i modify my code to achieve this? I dont need the data column.
CodePudding user response:
I have assumed that all 70 rows in the image are JSON.
This code does the job
df = pd.read_csv(<csv file path>)
new_data = []
for index in df.index:
row = eval(df.iloc[index, :].values[0])
new_data.append(row.values())
new_df = pd.DataFrame(new_data, columns = row.keys())
new_df = pd.concat([new_df, df["itemId"]], axis = 1)
Here I convert convert the JSON object in each row to a Python dictionary and then append it into a list. Once I have the whole list, I convert it into a pandas dataframe.
A shorter way to do this,
rows = list(map(eval, df["data"].values.ravel()))
vals = map(dict.values, rows)
new_df = pd.DataFrame(vals, columns = list(rows)[0].keys())
new_df = pd.concat([new_df, df["itemId"]], axis = 1)
The table I get -
| timestamp | avgHighPrice | avgLowPrice | highPriceVolume | lowPriceVolume | itemId | |
|---|---|---|---|---|---|---|
| 0 | 1644192000 | 74099578 | 73256019 | 285 | 347 | 13652 |
| 1 | 1644213600 | 74247533 | 73363183 | 145 | 209 | 13652 |
| 2 | 1644235200 | 74056407 | 73285468 | 190 | 230 | 13652 |
| 3 | 1644256800 | 73767754 | 73119554 | 354 | 275 | 13652 |
| 4 | 1644278400 | 73463445 | 72694429 | 374 | 299 | 13652 |