I am trying to get the best possible elapsed/slot time for a reasonably complex query.
The cross join part takes in a table which has a hhID, a brandID, and 2 other values (v1 and v2, for this example's sake).
I have to relate v1 and v2 from each brandID, to every other brandID (including itself), inside each hhID.
So, for example, if I have the following rows:
hhid brandID v1 v2
1 A 4 7
1 B 6 3
2 A 2 7
2 B 9 5
.
.
.
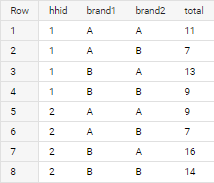
And I want the output to be something like:
hhid brand1 brand2 (brand1.v1 brand2.v2)
1 A A 4 7 = 11
1 A B 4 3 = 7
1 B A 6 7 = 13
1 B B 6 3 = 9
2 A A 2 7 = 9
2 A B 2 5 = 7
2 B A 9 7 = 16
2 B B 9 5 = 14
.
.
.
The input table can be quite big (hundreds of thousands of rows), which naturally results in an even bigger output table (upwards of a million rows).
Currently, I am simply self joining the table on hhID. I have looked into window functions, but I did not see a way to apply them here. I have also tried using UDFs, in a way to try to cache this table and allow for faster computation, but it resulted in essentially the same time.
This is by far the slowest part of my query as of now. How should I optimize this?
CodePudding user response:
Try below
select hhid,
t.brandid as brand1,
brand.brandID as brand2,
v1 brand.v2 as total
from (
select *,
array_agg(struct(brandID, v2)) over(partition by hhid) brands
from your_table
) t, unnest(brands) as brand
if applied to sample data in your question - output is