So here is my problem :
I have tons of doublons in my data, and I would like to count in SQL the number of times a column doesn't have the same value for a same id.
So, for example, if I have the following table :
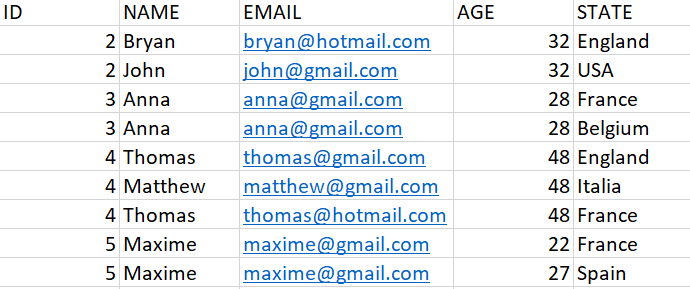
Here is the output I would like :
Name : 2
Email : 3
Age : 1
State : 5
Could someone please help me?
Keep in mind I have a lot more columns in my real data, so doing it one by one is not the best solution. I would like a code which can count it for all columns directly, but for the moment I didn't find a solution :/
Thank you, and take care of you!
CodePudding user response:
One possible solution for a specific column could look like:
select distinct Count(*) over()
from t
group by id
having Count(distinct name) > 1;
Result: 2
select distinct Count(*) over()
from t
group by id
having Count(distinct age) > 1;
Result: 1
If you can make use of window functions an example of counting multiple columns in a single query would be:
select
Count(distinct case when name1 != name2 then id end) NameCount,
Count(distinct case when age1 != age2 then id end) AgeCount
from (
select *,
Min(name) over(partition by id) name1,
Max(name) over(partition by id) name2,
Min(age) over(partition by id) age1,
Max(age) over(partition by id) age2
from t
)t;