I have the following Python Code:-
import pandas as pd
import requests
import numpy as np
from bs4 import BeautifulSoup
import xlrd
import re
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
res3 = requests.get("https://web.archive.org/web/20220521203053/https://www.military-
airshows.co.uk/press22/bbmfschedule2022.htm")
soup3 = BeautifulSoup(res3.content,'lxml')
BBMF_2022 = []
#BBMF_elem = soup3.find_all('a', string=re.compile(r'between|Flypast'))
for item in soup3.find_all('a', string=re.compile(r'between|Flypast')):
li1 = item.find_parent().text
#li2 = li1.find_previous().font
#print(link)
print(li1)
#print(li2)
#BBMF_2022.append(li1)
#df = pd.DataFrame(BBMF_2022, columns=['BBMF_2022'])
#df
The issue I have is when I run the Code, the Data is printed, for the 15 Entries from May 28th to May 29th, 15 times. I am not sure why that is the case? Could someone suggest for me the reason why? And tell me what I need to change in the Code, so that that Data is printed only once and not the 15 times? I have tried to Scrape Data from a Website, where entries contain the word between or Flypast in 'a' tags. The Printed Data is correct, i.e. for the entries for the 21st May they are printed only the once, and the appearance of the Data is correct.
I have inspected the Page data and have noticed <i> tags are not present in the 28th-29th May Data that are, in places in the 21st May data etc.
When I use these lines of Code instead:
for item in soup3.find_all('a', string=re.compile(r'between|Flypast')):
li1 = item.find_parent().text
#li2 = li1.find_previous().font
#print(link)
#print(li1)
#print(li2)
BBMF_2022.append(li1)
df = pd.DataFrame(BBMF_2022, columns=['BBMF_2022'])
df
The first entry for the 28th May, is printed out in the output DataFrame 15 times! Instead of 15 separate Entries from the 28th May to 29th May I mentioned before. I am confused as to where, I am going wrong with this? I am using a web.archive.org link, as the Data from a week ago was removed the other day, from the Website.
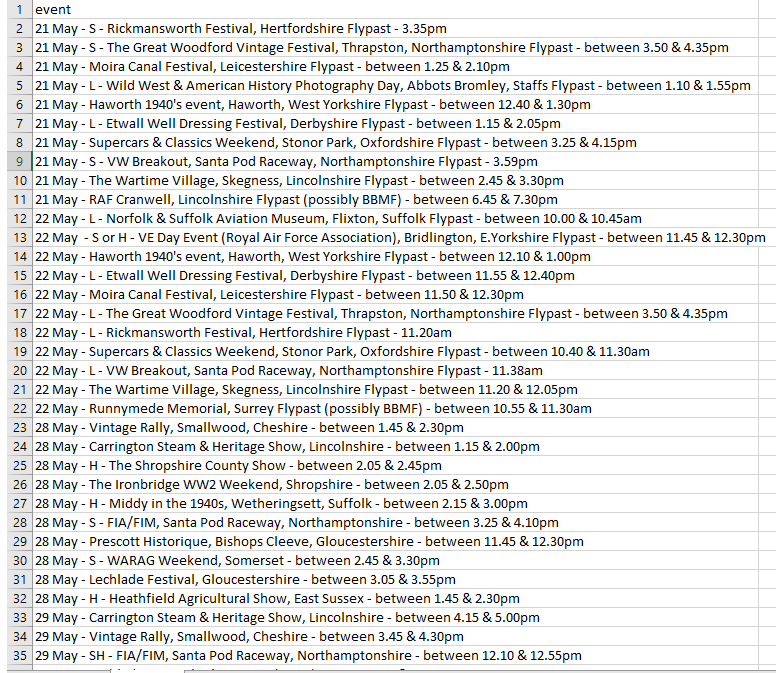
For the First used Python Code, the output I wan't is :-
21 May - S - Rickmansworth Festival, Hertfordshire Flypast - 3.35pm
21 May - S - The Great Woodford Vintage Festival, Thrapston, Northamptonshire Flypast - between 3.50 & 4.35pm
21 May - Moira Canal Festival, Leicestershire Flypast - between 1.25 & 2.10pm
21 May - L - Wild West & American History Photography Day, Abbots Bromley, Staffs Flypast - between 1.10 & 1.55pm
21 May - Haworth 1940's event, Haworth, West Yorkshire Flypast - between 12.40 & 1.30pm
21 May - L - Etwall Well Dressing Festival, Derbyshire Flypast - between 1.15 & 2.05pm
21 May - Supercars & Classics Weekend, Stonor Park, Oxfordshire Flypast - between 3.25 & 4.15pm
21 May - S - VW Breakout, Santa Pod Raceway, Northamptonshire Flypast - 3.59pm
21 May - The Wartime Village, Skegness, Lincolnshire Flypast - between 2.45 & 3.30pm
22 May - L - Norfolk & Suffolk Aviation Museum, Flixton, Suffolk Flypast - between 10.00 & 10.45am
22 May - S or H - VE Day Event (Royal Air Force Association), Bridlington, E.Yorkshire Flypast - between 11.45 & 12.30pm
22 May - Haworth 1940's event, Haworth, West Yorkshire Flypast - between 12.10 & 1.00pm
22 May - L - Etwall Well Dressing Festival, Derbyshire Flypast - between 11.55 & 12.40pm
22 May - Moira Canal Festival, Leicestershire Flypast - between 11.50 & 12.30pm
22 May - L - The Great Woodford Vintage Festival, Thrapston, Northamptonshire Flypast - between 3.50 & 4.35pm
22 May - L - Rickmansworth Festival, Hertfordshire Flypast - 11.20am
22 May - Supercars & Classics Weekend, Stonor Park, Oxfordshire Flypast - between 10.40 & 11.30am
22 May - L - VW Breakout, Santa Pod Raceway, Northamptonshire Flypast - 11.38am
22 May - The Wartime Village, Skegness, Lincolnshire Flypast - between 11.20 & 12.05pm
28 May - Vintage Rally, Smallwood, Cheshire - between 1.45 & 2.30pm
28 May - Carrington Steam & Heritage Show, Lincolnshire - between 1.15 & 2.00pm
28 May - H - The Shropshire County Show - between 2.05 & 2.45pm
28 May - The Ironbridge WW2 Weekend, Shropshire - between 2.05 & 2.50pm
28 May - H - Middy in the 1940s, Wetheringsett, Suffolk - between 2.15 & 3.00pm
28 May - S - FIA/FIM, Santa Pod Raceway, Northamptonshire - between 3.25 & 4.10pm
28 May - Prescott Historique, Bishops Cleeve, Gloucestershire - between 11.45 & 12.30pm
28 May - S - WARAG Weekend, Somerset - between 2.45 & 3.30pm
28 May - Lechlade Festival, Gloucestershire - between 3.05 & 3.55pm
28 May - H - Heathfield Agricultural Show, East Sussex - between 1.45 & 2.30pm
29 May - Carrington Steam & Heritage Show, Lincolnshire - between 4.15 & 5.00pm
29 May - Vintage Rally, Smallwood, Cheshire - between 3.45 & 4.30pm
29 May - SH - FIA/FIM, Santa Pod Raceway, Northamptonshire - between 12.10 & 12.55pm
29 May - Lechlade Festival, Gloucestershire - between 3.05 & 3.55pm
29 May - SH - Classic Wings & Wheels, Bidford Gliding Club, Warwickshire - between 12.30 & 1.00pm
02 June - L - Lanc, Tank and Military Machines, East Kirkby, Lincs. Flypast
02 July - S - Hollowell Steam and Vintage Rally Flypast - 12.48pm
03 July - SH - Hollowell Steam and Vintage Rally Flypast - 2.01pm
And I want the Same Output, when using the DataFrame lines of Code.
I tried the Latest Webpage for June. I would like the Output to be the Same format as that I posted for June. The problem with June's Data, is that the between and Flypast text is not in a 'a' href tag this time, so I am not sure how to combine re=compile line of Code with which relevant tag, it seems to be in a font tag ?
I used this line of Code for June instead :-
for item in soup3.find_all('b', string=re.compile(r'June')):
But as I am not including between and Flypast, in the line of Code, alot of unwanted Data is output. And as before, June's Data is repeated, as many times as there are entries.
CodePudding user response:
Well, that wasn't easy but here we are: (I did it for June because couldn't access May well but the code should work for May too)
1. Import modules, get url and html code:
from bs4 import BeautifulSoup
from lxml import etree
import requests
URL = "https://www.military-airshows.co.uk/press22/bbmfschedule2022.htm"
webpage = requests.get(URL)
soup = BeautifulSoup(webpage.content, "html.parser")
dom = etree.HTML(str(soup))
2. Get all the text() from the descendant after the first i:
all = dom.xpath('/html/body/div[6]/div/div[1]/div/div[2]/i[4]/descendant::text()')
2.1 For convenience I did here a first clean:
all = [i for i in all if i != '\n' and i != ' ']
3. I wrote a small function to let us delimit lines/rows every time a '•' occurs:
def split_list(input_list, delimiter):
result_list = []
while len(input_list) > 0:
elem = input_list.pop(0)
if elem == delimiter:
if 'sub_list' in locals():
result_list.append(sub_list)
sub_list = [elem]
elif len(input_list) == 0:
sub_list.append(elem)
result_list.append(sub_list)
else:
sub_list.append(elem)
return result_list
a = split_list(all, '•')
This function works for any separator you want, you can use it somewhere else ;)
4. Now we can use a for loop on our clean list to create a dataframe:
rows = []
for i in a:
date = (i[1])
event = (','.join(i[2:])).replace(',', '')
rows.append([date,event])
df = pd.DataFrame(rows, columns=["Date", "Event"])
df
5. Output:
| index | Date | Event |
|---|---|---|
| 0 | 02 June | - BBMF aircraft will take part in the Queen's Platinum Jubilee Flypast over Buckingham Palace at 1.00pm |
| 1 | 02 June | - Kingston-Upon-Hull E.Yorkshire - between 6.50 & 7.35pm |
| 2 | 02 June | - Hessle N.Yorkshire - between 6.45 & 7.30pm |
...
| index | Date | Event |
|---|---|---|
| 105 | 05 June | - Ingatestone Essex - between 12.45 & 1.30pm |
| 106 | 05 June | - Maidstone Kent - between 3.45 & 4.30pm |
| 107 | 05 June | - H - The Overlord Show Denmead Hampshire - between 3.10 & 4.00pm |
Please accept ✅ this answer if it solved your problem :)
Otherwise mention me (using @) in comment while telling me what's wrong ;)
CodePudding user response:
Given the irregularity of the html, and some of the entries, you will need to search initially for a couple of patterns (you are missing some dates completely with current pattern). This can be done with css OR syntax and passing a list of month abbreviations to search for within specified tags.
You would then handle the returned list according to tag type. In the case of b tags, you can construct the relevant event entry from each matched node plus a number of siblings.
I use the bullets as a sort of anchor, to identify my target elements, and then use further css selectors to limit to just those of interest on the page.
Given the nature of the html, the solution below is more brittle than I would like.
import requests
from bs4 import BeautifulSoup as bs
import calendar
import pandas as pd
months = '" ' '"," '.join(list(calendar.month_abbr)[1:]) '"'
r = requests.get(
'https://web.archive.org/web/20220521203053/https://www.military-airshows.co.uk/press22/bbmfschedule2022.htm')
soup = bs(r.content, 'lxml')
results = []
for i in soup.select(f'[color=black]:-soup-contains("•") ~ i:has(b:-soup-contains({months})), \
[color=black]:-soup-contains("•") b:-soup-contains({months}):not(i [color=black]:-soup-contains("•") \
b:-soup-contains({months}))'):
if i.name != 'b':
if '\n' in i.text: # handle odd case of late May
results.extend(i.text.replace('• ', '').strip().split('\n'))
else:
results.append(i.text.replace('• ', '').strip())
else:
s = i.text i.next_sibling i.next_sibling.find_next(string=True)
ss = i.next_sibling.find_next(string=True).find_next(string=True)
if ss.strip() == '-':
results.append(s ss ss.find_next('a').text.strip())
else:
results.append(s.strip())
df = pd.DataFrame(results, columns=['event'])
df.to_markdown(index=False)
df.to_csv('events.csv', encoding='utf-8-sig', index=False)
Late May:
Has a lot of br separated listings within a single parent i tag
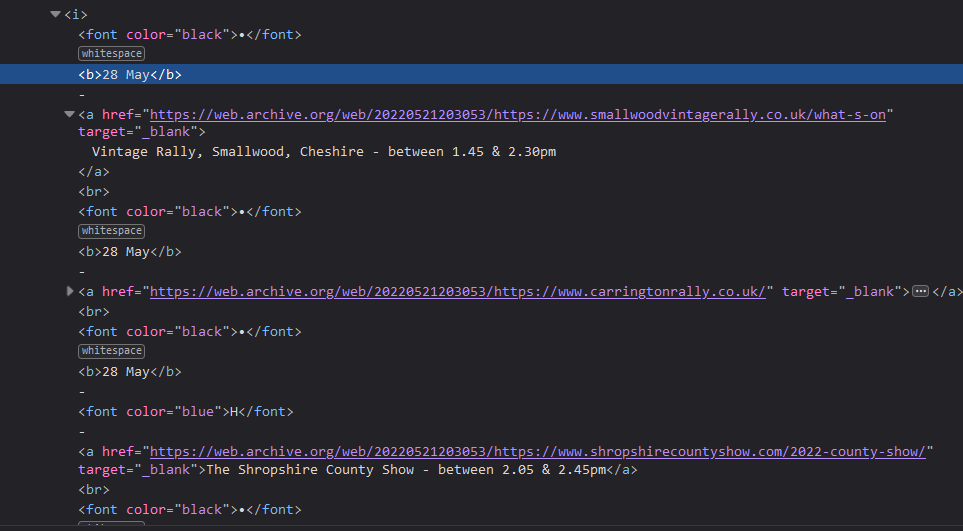
I split this content on \n then extend my overall results with this list, at the appropriate point.
Sample of results: