I have a dataframe similar to:
| NAME | DB1 | DB2 | DB3 | DB4 |
|---|---|---|---|---|
| WORKFLOW_1 | workflow1-1.jar | workflow1-2.jar | workflow1-1.jar | workflow1-3.jar |
| WORKFLOW_2 | workflow2-1.jar | workflow2-1.jar | workflow2-1.jar | workflow2-1.jar |
| WORKFLOW_3 | workflow3-2.jar | workflow3-1.jar | workflow3-1.jar | workflow3-1.jar |
| WORKFLOW_4 | workflow4-1.jar |
Where NAME is the key for this table throughout n databases. I'm gathering data from an specific column and merging it side by side for further analysis.
My problem is that I need to highlight rows which contains different filenames between columns DBn.
I've tried the solution below:
def highlight(row):
for key1, column1 in row.items():
if key1 != 'NAME':
for key2, column2 in row.items():
if key2 != 'NAME':
if column1 != column2:
return ['background-color: red']
return ['background-color: green']
pd = pd.style.apply(highlight)
I tried to style the entire row when at least one filename is different from the others, but it did not work, when I export to excel, only the first line is red, which is not even one of the cases where it should happen.
CodePudding user response:
The simplest (and naïve) approach is to use 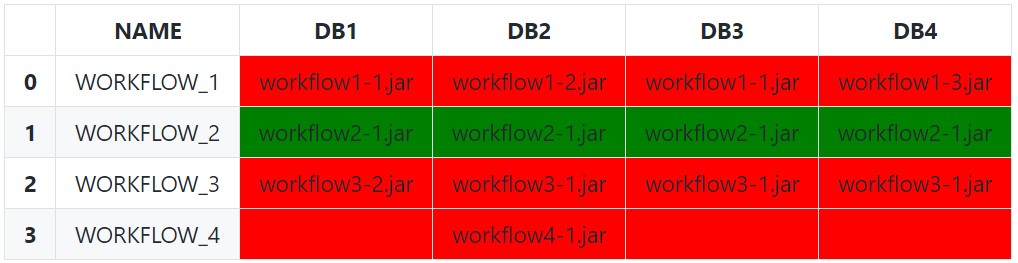
We can be a bit less naïve by excluding empty string and null values (and any other invalid values) from each row with a boolean indexing before doing the equality comparison with just the filtered array:
def highlight_row(s: pd.Series) -> List[str]:
filtered_s = s[s.notnull() & ~s.eq('')]
# Check for completely empty row (prevents index error from filtered_s[0])
if filtered_s.empty:
# No valid values in row
css_str = ''
elif filtered_s.eq(filtered_s[0]).all():
# All values are the same
css_str = 'background-color: green'
else:
# Row Values Differ
css_str = 'background-color: red'
return [css_str] * len(s)
We can also leverage an 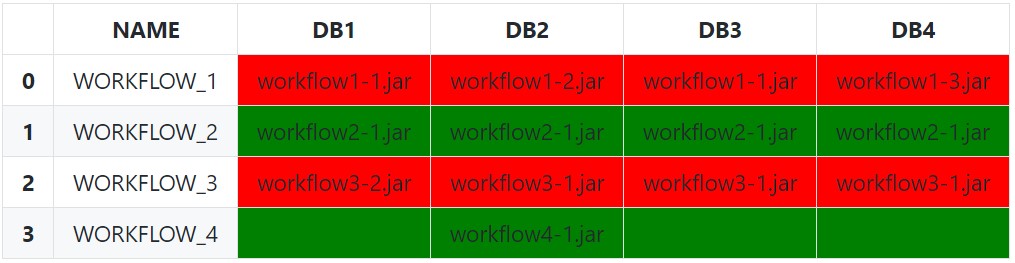
Lastly, it is possible to instead pass the idx/cols to the styling function instead of subsetting if wanting the entire row to be highlighted:
def highlight_row(s: pd.Series, idx: pd.IndexSlice) -> List[str]:
css_str = 'background-color: red'
# Filter Columns
filtered_s = s[idx]
# Filter Values
filtered_s = filtered_s[filtered_s.notnull() & ~filtered_s.eq('')]
# Check for completely empty row
if filtered_s.empty:
css_str = '' # Empty row Styles
elif filtered_s.eq(filtered_s[0]).all():
css_str = 'background-color: green'
return [css_str] * len(s)
df.style.apply(
func=highlight_row,
idx=pd.IndexSlice['DB1':], # 1D IndexSlice!
axis=1
)
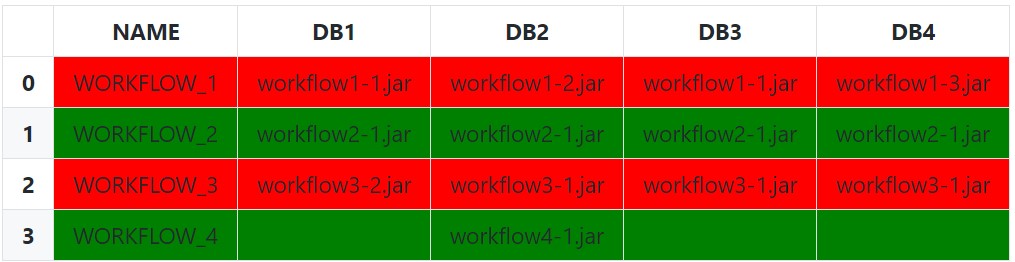
Setup and Imports:
from typing import List
import pandas as pd # version 1.4.2
df = pd.DataFrame({
'NAME': ['WORKFLOW_1', 'WORKFLOW_2', 'WORKFLOW_3', 'WORKFLOW_4'],
'DB1': ['workflow1-1.jar', 'workflow2-1.jar', 'workflow3-2.jar', ''],
'DB2': ['workflow1-2.jar', 'workflow2-1.jar', 'workflow3-1.jar',
'workflow4-1.jar'],
'DB3': ['workflow1-1.jar', 'workflow2-1.jar', 'workflow3-1.jar', ''],
'DB4': ['workflow1-3.jar', 'workflow2-1.jar', 'workflow3-1.jar', '']
})