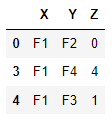
Suppose I have the following dataframe
| X | Y | Z |
|---|---|---|
| F1 | F2 | 0 |
| F1 | F3 | 2 |
| F1 | F2 | 1 |
| F1 | F4 | 4 |
| F1 | F3 | 1 |
and want to convert this into the following
| X | Y | Z |
|---|---|---|
| F1 | F2 | 0 |
| F1 | F4 | 4 |
| F1 | F3 | 1 |
Here i want to remove the rows that have same values in X and Y columns keeping the one whose value in the Z column is lowest.How can I do this? Thank you in advance!!
CodePudding user response:
Try this
index of smallest Z values per X-Y pair
idx = df.groupby(['X', 'Y'])['Z'].idxmin().sort_values()
# filter
df.loc[idx]