I have a dataframe like so
dfDictionary = {'Results':['Home',
'Away',
'For',
'Against'
],
'info':[ '-', '-','-','-',],
'rating':[ '-', '-','-','-',],
'review':[ '-', '-','-','-',]}
dfTable1 = pd.DataFrame(dfDictionary)
It looks like below
Results info rating review
0 Home - - -
1 Away - - -
2 For - - -
3 Against - - -
I created a MultiIndex dataframe from this df like so dfTable1.index =pd.MultiIndex.from_product([[f'Summary1'], dfTable1.Results])
Now the dataframe looks like below. As you can see, the Results column is in both Index & column. I do not want the column anymore since it is in index, How do I do that with dropping? I ask "without dropping" because I do not want 2 levels in the column.
Results info rating review
Results
Summary1 Home Home - - -
Away Away - - -
For For - - -
Against Against - - -
I have another df almost exactly same
dfTable2 = pd.DataFrame(dfDictionary)
dfTable2.index =pd.MultiIndex.from_product([[f'Summary2'], dfTable1.Results])
And eventually I want to concatenate them with resultsTable = pd.concat([dfTable1, dfTable2], axis = 0)
Right now I get a dataframe like the pic below
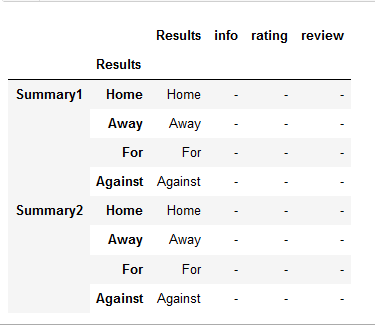
What I want to achieve in the end is a df like below with a header column & I would do that with resultsTable.columns =pd.MultiIndex.from_product([[f'Final Consolidated Table'], resultsTable.columns]). But before that I need to sort the issue I have currently.
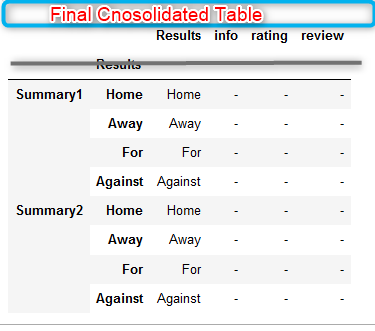
Update
With the initial solution provided by @jezrael, I was able to get the df like below after concatenating the 2 dataframes.
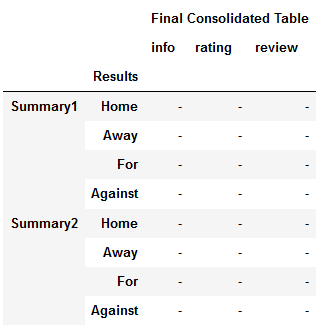
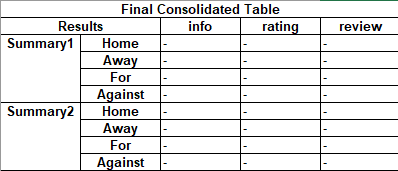
Is there any way to get a dataframe like below? Basically I am trying to recreate a pandas df similar to the excel table. If this is possible, it would be great.
CodePudding user response:
Use concat with convert Results to index by dictonary for first level Summary1:
dfTable1 = pd.DataFrame(dfDictionary)
dfTable1 = pd.concat({'Summary1':dfTable1.set_index('Results')})
print (dfTable1)
info rating review
Results
Summary1 Home - - -
Away - - -
For - - -
Against - - -
Your solution working with DataFrame.pop for use and drop Results:
dfTable1.index = pd.MultiIndex.from_product([[f'Summary1'], dfTable1.pop('Results')])
print (dfTable1)
info rating review
Results
Summary1 Home - - -
Away - - -
For - - -
Against - - -
Working like removed by drop:
dfTable1.index = pd.MultiIndex.from_product([[f'Summary1'], dfTable1.Results])
dfTable1 = dfTable1.drop('Results', axis=1)
print (dfTable1)
info rating review
Results
Summary1 Home - - -
Away - - -
For - - -
Against - - -
EDIT:
dfDictionary = {'Results':['Home',
'Away',
'For',
'Against'
],
'info':[ '-', '-','-','-',],
'rating':[ '-', '-','-','-',],
'review':[ '-', '-','-','-',]}
dfTable1 = pd.DataFrame(dfDictionary)
dfTable2 = pd.DataFrame(dfDictionary)
dfTable1 = pd.concat({'Summary1':dfTable1.set_index('Results')})
dfTable2 = pd.concat({'Summary2':dfTable2.set_index('Results')})
resultsTable = pd.concat([dfTable1, dfTable2])
For expected ouput is necessary create helper DataFrame from columns names, for merged cells for Results is created 3 levels MultiIndex.
Then is separately written first header and and data without columns names:
d = {'level_0':'Results'}
header = resultsTable.reset_index().columns.to_frame().rename(index=d).replace({0:d})
header = pd.concat({'Final Consolidated Table':header.set_index(0, append=True)}).T.rename_axis([None, None, None], axis=1)
resultsTable = resultsTable.rename_axis([None, None])
with pd.ExcelWriter('output.xlsx') as writer:
header.to_excel(writer, startcol=-1)
resultsTable.to_excel(writer, startrow=2, header=None)