I have a huge data to read based on two headers, But when I am using multi-index approach I am unable to use 'usecols' in pandas dataframe.
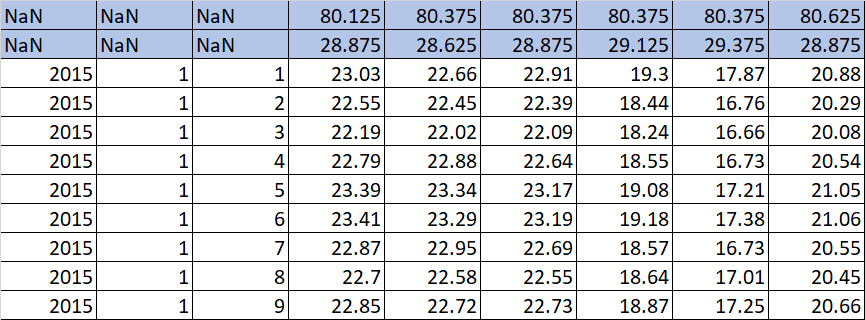
when I am using
df = pd.read_csv(files, delimiter=' ', header=[0,1])
it is taking too much of time and memory
another approach I am trying to use is
df = pd.read_csv(files, delimiter=' ', usecols = ["80.375"])
it is taking only one colomn, rather it should take all the four colomn with header '80.375'
Desired output
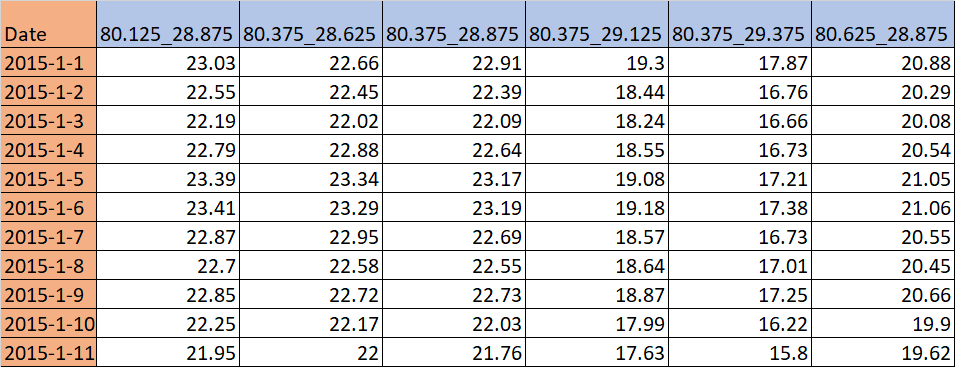
Please suggest any alternative approach
Thanks in advance
CodePudding user response:
You can use two pass to extract data and headers.
# read_csv common options
opts = {'sep': ' ', 'header': None}
# Extract headers, create MultiIndex
headers = pd.read_csv('data.csv', **opts, nrows=2)
mi = pd.MultiIndex.from_frame(headers.T)
# Keep desired columns
dti = [0, 1, 2] # Year, Month, Day
cols = mi.get_locs([80.375]).tolist()
# Build dataframe
df = pd.read_csv('data.csv', **opts, skiprows=2, index_col=dti, usecols=dti cols)
df.columns = mi[cols]
df = df.rename_axis(index=['Year', 'Month', 'Day'], columns=['Lvl1', 'Lvl2'])
df.index = pd.to_datetime(df.index.to_frame()).rename('DateTime')
Output:
>>> df
Lvl1 80.375
Lvl2 28.625 28.875 29.125 29.375
DateTime
2015-01-01 21 22 23 24
2015-01-02 31 32 33 34
2015-01-03 41 42 43 44
2015-01-04 51 52 53 54
Input csv file:
80.125 80.375 80.375 80.375 80.375 80.625
28.875 28.625 28.875 29.125 29.375 28.875
2015 1 1 20 21 22 23 24 25
2015 1 2 30 31 32 33 34 35
2015 1 3 40 41 42 43 44 45
2015 1 4 50 51 52 53 54 55
Update
I need to convert the output in single header row.
# Extract headers, create MultiIndex
headers = pd.read_csv('data.csv', sep=' ', header=None, nrows=2)
mi = pd.MultiIndex.from_frame(headers.T)
# Keep desired columns
dti_cols = [0, 1, 2] # Year, Month, Day
dti_names = ['Year', 'Month', 'Day']
dat_cols = mi.get_locs([80.375]).tolist()
dat_names = mi[cols].to_flat_index().map(lambda x: f"{x[0]}_{x[1]}").tolist()
# Build dataframe
df = (pd.read_csv('data.csv', sep=' ', header=None, skiprows=2,
usecols=dti_cols dat_cols, names=dti_names dat_names,
parse_dates={'Date': ['Year', 'Month', 'Day']}))
Output:
>>> df
Date 80.375_28.625 80.375_28.875 80.375_29.125 80.375_29.375
0 2015-01-01 21 22 23 24
1 2015-01-02 31 32 33 34
2 2015-01-03 41 42 43 44
3 2015-01-04 51 52 53 54