I have the following data format:
name role startdate enddate
abby associate 2/15/2010 6/13/2012
bobby intern 6/21/2013 1/10/2014
james manager 2/12/2012 5/13/2015
I want to create a year dummy variable for the startdate and enddate range (e.g. 2010=1 if the startdate and enddate is within 1/1/2010 - 12/31/2010 range, so that it will generate the following output:
name role startdate enddate 2010 2011 2012
abby associate 2/15/2010 6/13/2012 1 1 1
bobby intern 6/21/2013 1/10/2014 0 0 0
james manager 2/12/2012 5/13/2015 0 0 1
Thank you in advance
CodePudding user response:
You have to implement function from scratch
# Change to pandas datetime type
df[['startdate','enddate']] = df[['startdate','enddate']].apply(pd.to_datetime, infer_datetime_format=True)
# take years from date columns
df['startdate_year'] =pd.DatetimeIndex(df['startdate']).year
df['enddate_year'] =pd.DatetimeIndex(df['enddate']).year
## min and max values of column
min = df['startdate_year'].min()
max =df['enddate_year'].max()
# creating dictionary
year_dict = {k: [] for v, k in enumerate([i for i in range(min,max 1)])}
#{2010: [], 2011: [], 2012: [], 2013: [], 2014: [], 2015: []}
def getdummi(start,end):
values = [i for i in range(start,end 1)]
return [1 if i in values else 0 for i in year_dict.keys()]
# getdummi(2012,2014)
#[0, 0, 1, 1, 1, 0]
data = []
for index,row in df.iterrows():
data.append(getdummi(row['startdate_year'],row['enddate_year']))
dfdummi =pd.DataFrame(data,columns=list(year_dict.keys()))
dfdummi
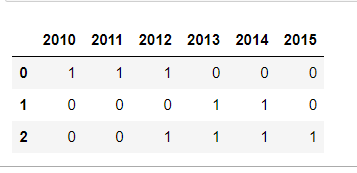
Then concat result in pandas
df = pd.concat([df,dfdummi],axis=1)
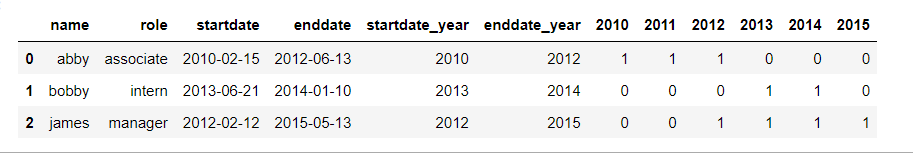
CodePudding user response:
creating dummy dataframe with just start and end year
df_test = pd.DataFrame([[2012,2014],[2015,2017],[2010, 2020]], columns= ['start_date', 'end_date'])
#make sure to convert year column to numerical value , and use pandas loc function to assign new column with value 1
for current_col in range(min_year, max_year 1):
df_test.loc[(df_test['start_date']<=current_col) & (df_test['end_date']>=current_col), current_col] = 1
fill blank value with zero
df_test = df_test.fillna(0)
you will get the desired output