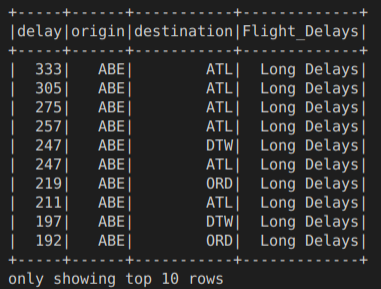
When I run
spark.sql("""SELECT delay, origin, destination,
CASE
WHEN delay > 360 THEN 'Very Long Delays'
WHEN delay > 120 AND delay < 360 THEN 'Long Delays'
WHEN delay > 60 AND delay < 120 THEN 'Short Delays'
WHEN delay > 0 and delay < 60 THEN 'Tolerable Delays'
WHEN delay = 0 THEN 'No Delays'
ELSE 'Early'
END AS Flight_Delays
FROM us_delay_flights_tbl
ORDER BY origin, delay DESC""").show(10)
I get
However, when I run
(df.select("delay","origin",col("destination"),
when(df.delay > 360,"Very Long Delays")
.when((df.delay > 120) & (df.delay < 360),"Long Delays")
.when((df.delay > 60) & (df.delay < 120),"Short Delays")
.when((df.delay > 0) & (df.delay < 60),"Tolerable Delays")
.when((df.delay == 0),"No Delays")
.otherwise("Early")
)
.orderBy(asc("ORIGIN"),desc("delay"))
).show(10)
I get
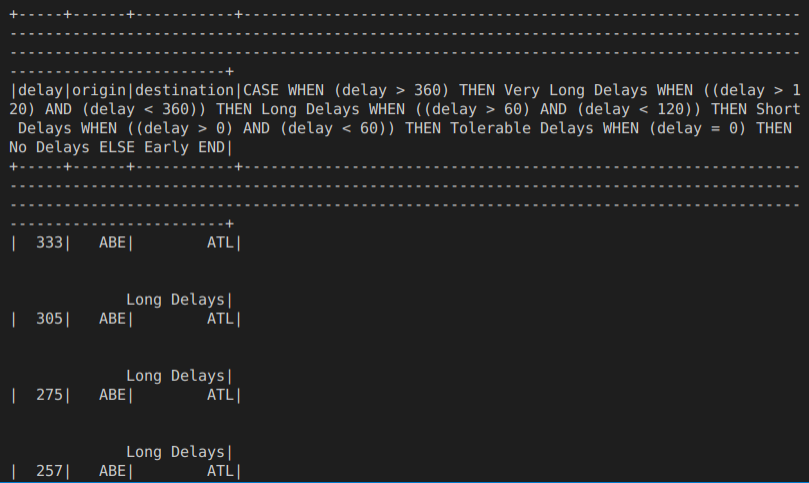
The results seem to be the same, except for the strange format. Due to space constraints, the remaining results are not shown.
Why is this happening? And how can I solve it?
The data can be found on this repo.
CodePudding user response:
Missing alias in the when expression
(df.select("delay","origin",col("destination"),
when(df.delay > 360,"Very Long Delays")
.when((df.delay > 120) & (df.delay < 360),"Long Delays")
.when((df.delay > 60) & (df.delay < 120),"Short Delays")
.when((df.delay > 0) & (df.delay < 60),"Tolerable Delays")
.when((df.delay == 0),"No Delays")
.otherwise("Early").alias("Flight_Delays")
)
.orderBy(asc("ORIGIN"),desc("delay"))).show(10)