I am trying to convert a python function to PySpark user defined function as below:
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf,col,array
from pyspark.sql.types import StringType,IntegerType,DecimalType
from datetime import date
def calculateAmount(loandate,loanamount):
y,m,d = loandate.split('-')[0],loandate.split('-')[1],loandate.split('-')[2]
ld = date(int(y),int(m),int(d))
if (date(2010,1,1) <= ld <= date(2015,12,31)):
fine = 10
elif (date(2016,1,1) <=ld <= date.today()):
fine = 5
return ((100 fine)*int(loanamount))/100
spark = SparkSession.builder.appName("User Defined Functions").getOrCreate()
df = spark.read.options(delimiter = "\t",header = True).csv("../input/applicationloan/loan.txt")
calAmount = udf(lambda interest,amount : calculateAmount(interest,amount),DecimalType())
df = df.withColumn("NewLoanAmount",calAmount(col("loandate"),col("loanamount")))
df.show()
Output of above code is below:
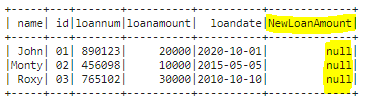
Screenshot of source file "loan.txt":
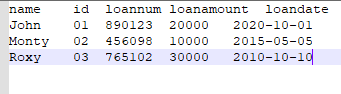
The above source file is tab delimited.
I am creating a new column "NewLoanAmount" using PySpark udf. But PySpark udf is returning me "NULL" values. It seems to be an issue with calling of lambda function in the PySpark udf.
How to write PySpark UDF with multiple parameters? I understand writing PySpark UDF with single parameter. But working with multiple parameters seems to be confusing.
CodePudding user response:
With your data, you should not create UDF. It's easily done using native Spark functions:
from pyspark.sql import functions as F
df = spark.createDataFrame(
[('John', '01', '89', 20000, '2020-10-01'),
('Monty', '02', '45', 10000, '2015-05-05'),
('Roxy', '03', '76', 30000, '2010-10-10')],
['name', 'id', 'loannum', 'loanamount', 'loandate'])
def calculateAmount(loandate, loanamount):
fine = F.when(F.col('loandate').between('2010-01-01', '2015-12-31'), 10) \
.when(F.col('loandate').between('2016-01-01', F.current_date()), 5)
return ((100 fine) * F.col('loanamount').cast('long')) / 100
df = df.withColumn("NewLoanAmount", calculateAmount("loandate", "loanamount"))
df.show()
# ----- --- ------- ---------- ---------- -------------
# |name |id |loannum|loanamount|loandate |NewLoanAmount|
# ----- --- ------- ---------- ---------- -------------
# |John |01 |89 |20000 |2020-10-01|21000.0 |
# |Monty|02 |45 |10000 |2015-05-05|11000.0 |
# |Roxy |03 |76 |30000 |2010-10-10|33000.0 |
# ----- --- ------- ---------- ---------- -------------
To answer the original question...
You already have the function definition, so lambda is not needed. And overall, it's simpler to use the decorator @udf instead of the line
calAmount = udf(lambda interest,amount : calculateAmount(interest,amount),DecimalType())
The following works:
from pyspark.sql.functions import udf, col, array
from pyspark.sql.types import StringType, IntegerType, DecimalType
from datetime import date
df = spark.createDataFrame(
[('John', '01', '89', 20000, '2020-10-01'),
('Monty', '02', '45', 10000, '2015-05-05'),
('Roxy', '03', '76', 30000, '2010-10-10')],
['name', 'id', 'loannum', 'loanamount', 'loandate'])
@udf
def calculateAmount(loandate, loanamount):
y, m, d = loandate.split('-')[0], loandate.split('-')[1], loandate.split('-')[2]
ld = date(int(y), int(m), int(d))
if (date(2010, 1, 1) <= ld <= date(2015, 12, 31)):
fine = 10
elif (date(2016, 1, 1) <= ld <= date.today()):
fine = 5
return ((100 fine) * int(loanamount)) / 100
df = df.withColumn("NewLoanAmount", calculateAmount(col("loandate"), col("loanamount")))
df.show()
# ----- --- ------- ---------- ---------- -------------
# |name |id |loannum|loanamount|loandate |NewLoanAmount|
# ----- --- ------- ---------- ---------- -------------
# |John |01 |89 |20000 |2020-10-01|21000.0 |
# |Monty|02 |45 |10000 |2015-05-05|11000.0 |
# |Roxy |03 |76 |30000 |2010-10-10|33000.0 |
# ----- --- ------- ---------- ---------- -------------
A way without the @udf decorator:
calAmount = udf(calculateAmount)
or
calAmount = udf(calculateAmount, DoubleType())
In your original code, you provide DecimalType(), but Python does not do calculations in decimal numbers. Your calculations are done on double precision numbers, not decimals. So, your result is a double precision number, while Spark expects to get a decimal number... This is why you get nulls. To make the python function to return a decimal, you would need to use decimal library. Without it, it's just double precision numbers.